Introduction to Statistical Learning
ACTL3142 & ACTL5110 Statistical Machine Learning for Risk Applications
Some of the figures in this presentation are taken from "An Introduction to Statistical Learning, with applications in R" (Springer, 2013) with permission from the authors: G. James, D. Witten, T. Hastie and R. Tibshirani
Data Science Skills
Actuaries use data for good
What is statistical (machine) learning?

What is statistical (machine) learning?
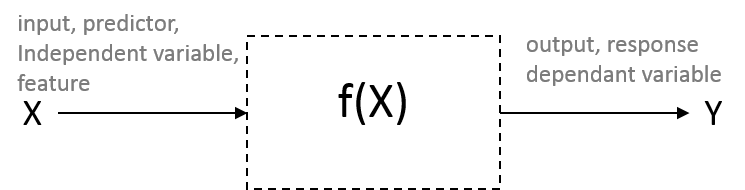
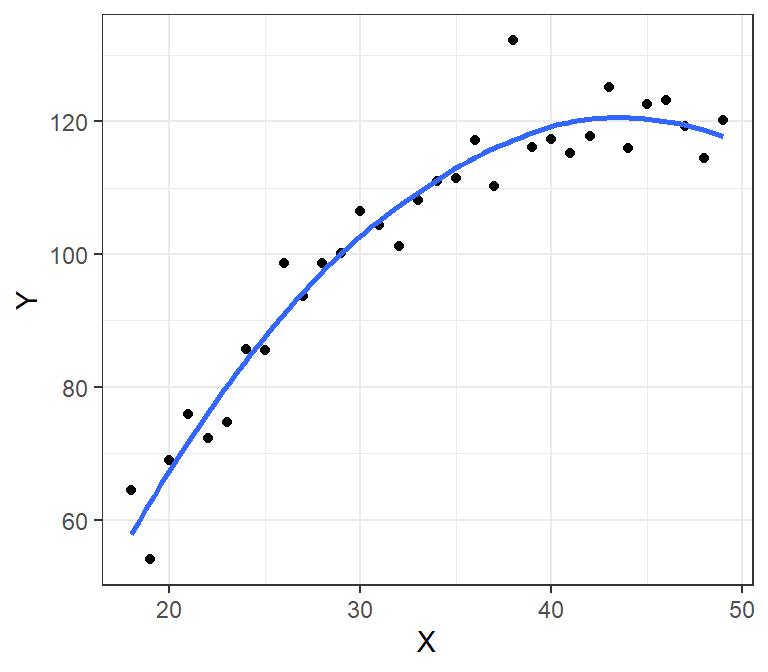
Example: Linear model fit on income data
Using Education and Seniority to explain Income:

- Linear model fitted
- Does a pretty decent job of fitting the data, by the looks of it, but doesn’t capture everything
Example: “perfect” fit on income data

- Non-parametric spline fit
- Fits the data perfectly: this is indicative of overfitting
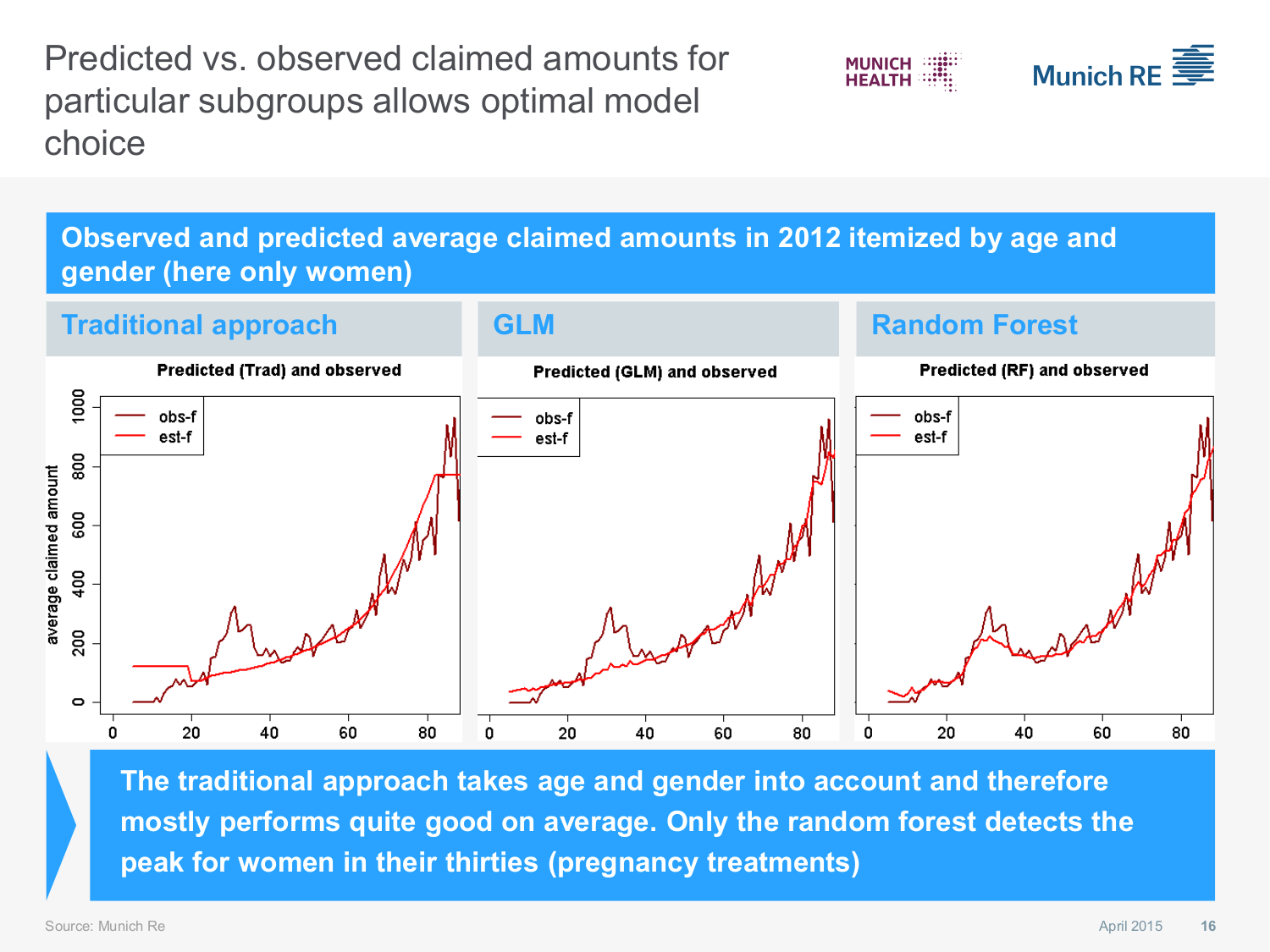
Actuarial Application: Health Insurance model choice
Tradeoff between interpretability and flexibility
- We will cover a number of different methods in this course
- They each have their own (relative) combinations of interpretability and flexibility:

Cluster analysis is a form of unsupervised learning

- The idea is to identify clusters: groups of points that are “similar”.
- Here, for illustration we have provided the real groups (in different colours), but in reality the actual grouping is not known in an unsupervised problem. Hence, “we are in some sense working blind” (James et al., 2021).
- The example of the right would be more difficult to cluster properly.
Actuarial Application: predict claim fraud and abuse

A note re Regression vs Classification problems
Regression
- Y is quantitative
- Examples: Sales prediction, claim size prediction, stock price modelling
Classification
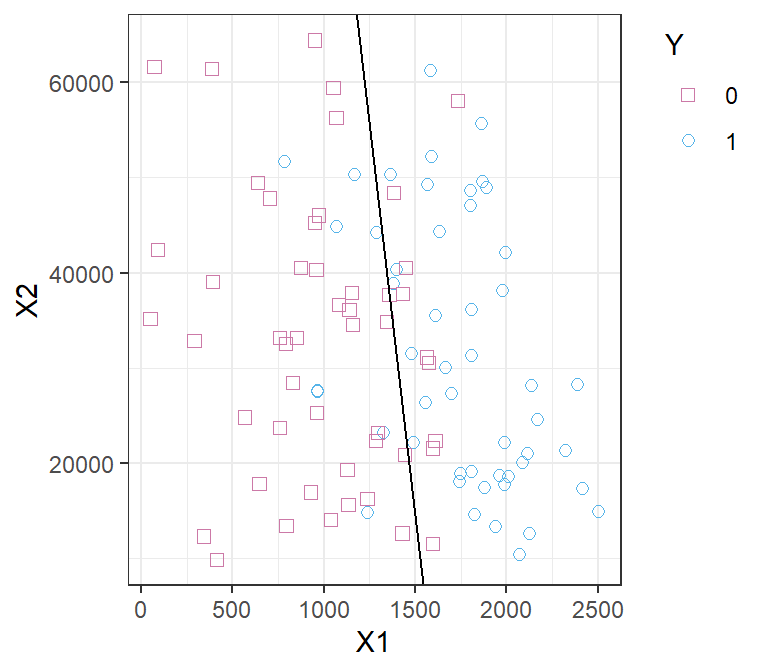
- Y is qualitative (or “categorial”, or “discrete”)
- Examples: fraud detection, face recognition, death
Example: which model is best?
- On the left plot, the true function f() is the black line, used to generate a sample of (X,Y), displayed as a scatterplot. Three different fitted models are illustrated as the blue, green and orange lines. On the right plot, training MSE (gray) and test MSE (red) of the respetive models are displayed.
![]()

K-nearest neighbours - illustration

K-nearest neighbours example, K=10

(purple is the Bayes boundary, black is the KNN boundary with K=10)
K-nearest neighbours example, K=1, K=100

James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An Introduction to Statistical Learning: with Applications in R. Springer.