Logistic Regression and Poisson Regression
ACTL3142 & ACTL5110 Statistical Machine Learning for Risk Applications
Some of the figures in this presentation are taken from "An Introduction to Statistical Learning, with applications in R" (Springer, 2013) with permission from the authors: G. James, D. Witten, T. Hastie and R. Tibshirani
Regression vs. classification
Regression
- Y is quantitative
- Examples: Sales prediction, claim size prediction, stock price modelling
Classification
- Y is qualitative (or “categorial”, or “discrete”)
- Examples: fraud detection, face recognition, death
Example: Predicting defaults (Default from ISLR2)


default(Y) is a binary variable (yes/no as 1/0)- Annual
income(X_1) and credit cardbalance(X_2) are continuous predictors student(X_3) is a categorical predictor
Simple linear regression on Default data:

Classification problems
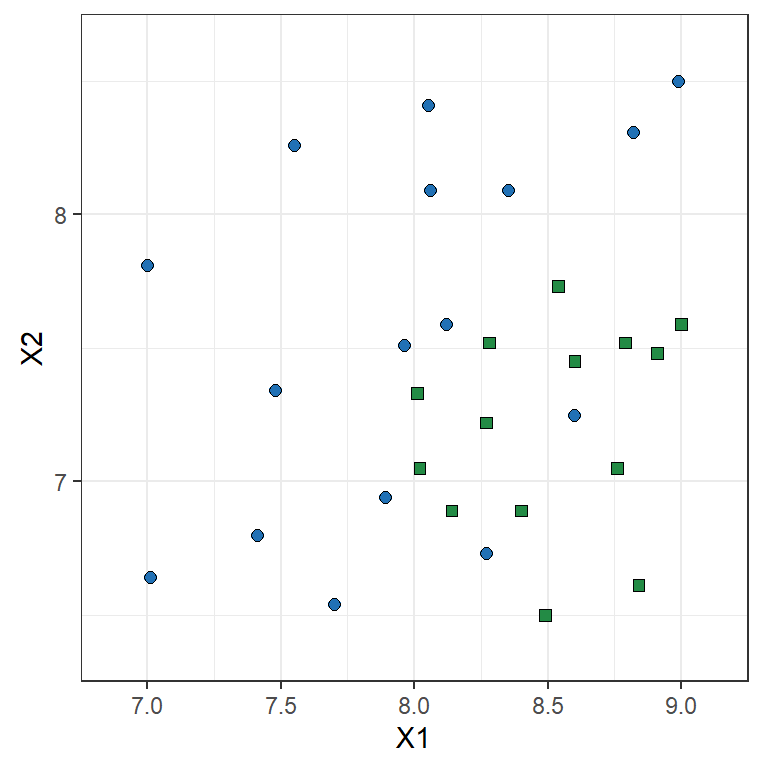
Coding in the binary case is simple Y \in \{0,1\} \Leftrightarrow Y\in\{{\color{#2171B5}\bullet},{\scriptsize{\color{#238B45}\blacksquare}}\}
Our objective is to find a good predictive model f that can:
- Estimate the probability \mathbb{P}(Y=1|X) \in [0, 1] as a certain f(X) f(X)\rightarrow [0,1] \Leftrightarrow {\color{#2171B5}\bullet}{\color{#6BAED6}\bullet}{\color{#BDD7E7}\bullet}{\color {#EFF3FF}\bullet}{\color{#EDF8E9}\bullet}{\color{#BAE4B3}\bullet}{\color{#74C476}\bullet}{\color {#238B45}\bullet}
- Classify observation f(X)\rightarrow \hat{Y}\in\{{\color{#2171B5}\bullet},{\scriptsize{\color{#238B45}\blacksquare}}\}
In summary…

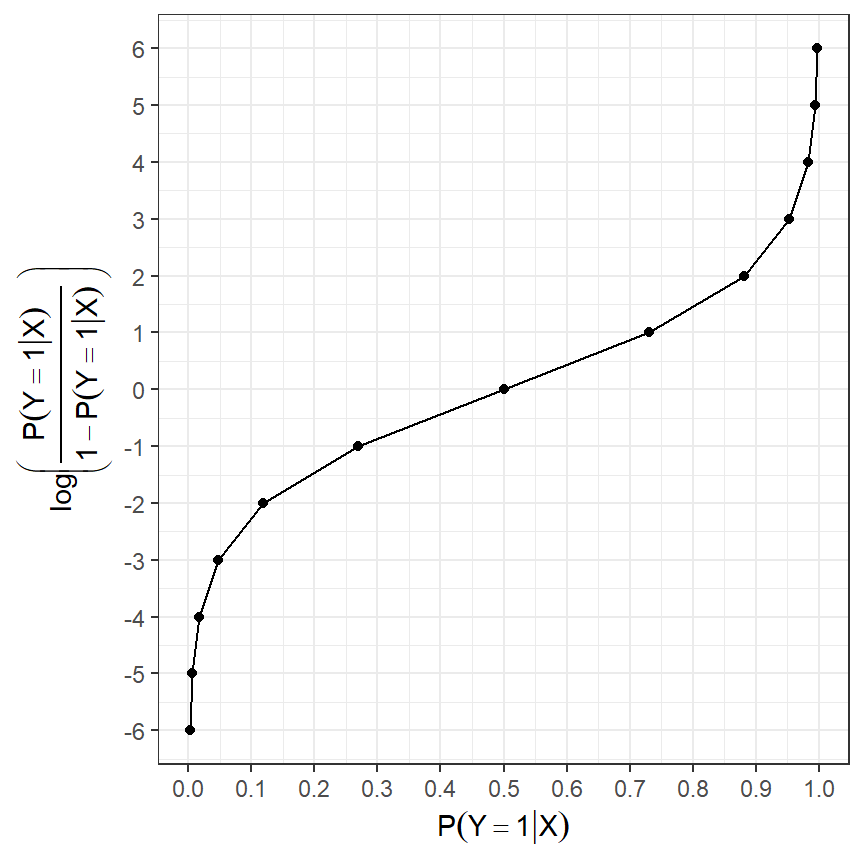
Probabilities, odds and log-odds
- We also have a bijection between probability and log-odds.
| probability | odds | logodds |
|---|---|---|
| 0.001 | 0.001 | -6.907 |
| 0.250 | 0.333 | -1.099 |
| 0.333 | 0.500 | -0.693 |
| 0.500 | 1.000 | 0.000 |
| 0.667 | 2.000 | 0.693 |
| 0.750 | 3.000 | 1.099 |
| 0.999 | 999.000 | 6.907 |
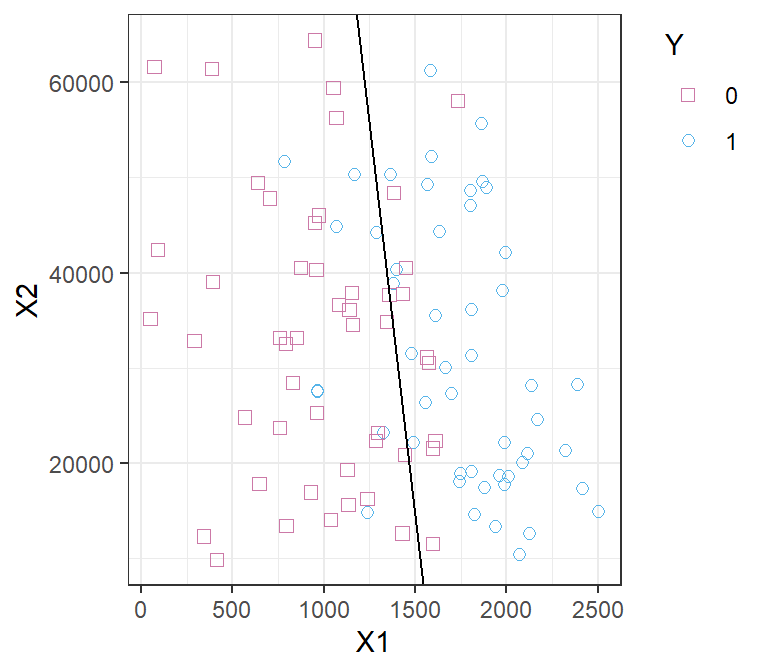
Toy example: Logistic Regression
Y = \begin{cases} 1 & \text{if } {\color{#2171B5}\bullet} \\ 0 & \text{if } {\scriptsize{\color{#238B45}\blacksquare}} \end{cases} \qquad \ln\left(\frac{\mathbb{P}(Y=1|X)}{1-\mathbb{P}(Y=1|X)}\right) = \beta_0 + \beta_1 X_1 + \beta_2 X_2
The parameter estimates are \hat{\beta}_0= 13.671, \hat{\beta}_1= -4.136, \hat{\beta}_2= 2.803
\hat{\beta}_1= -4.136 implies that the bigger X_1 the lower the chance it is a blue point
\hat{\beta}_2= 2.803 implies that the bigger X_2 the higher the chance it is a blue point
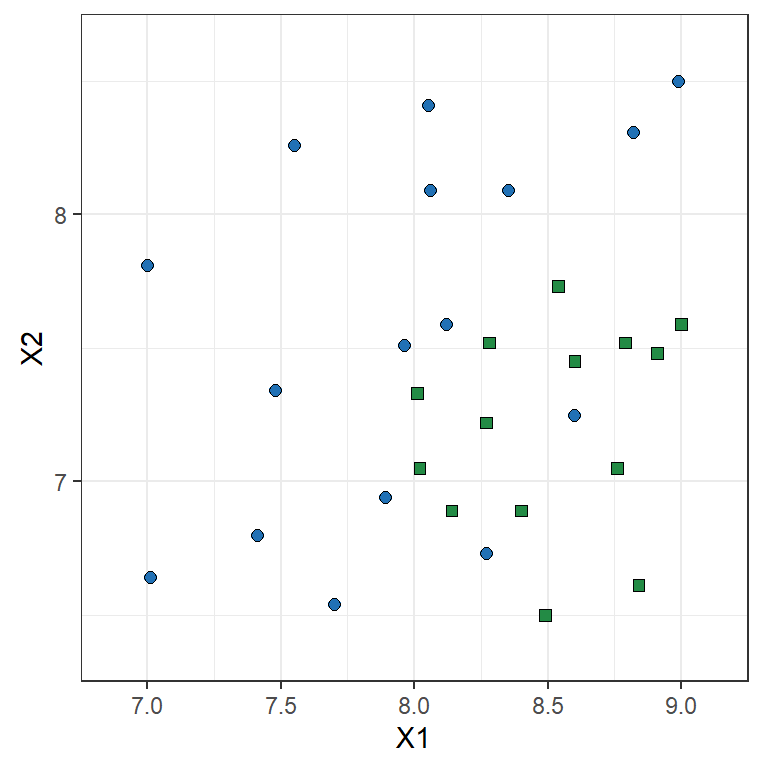
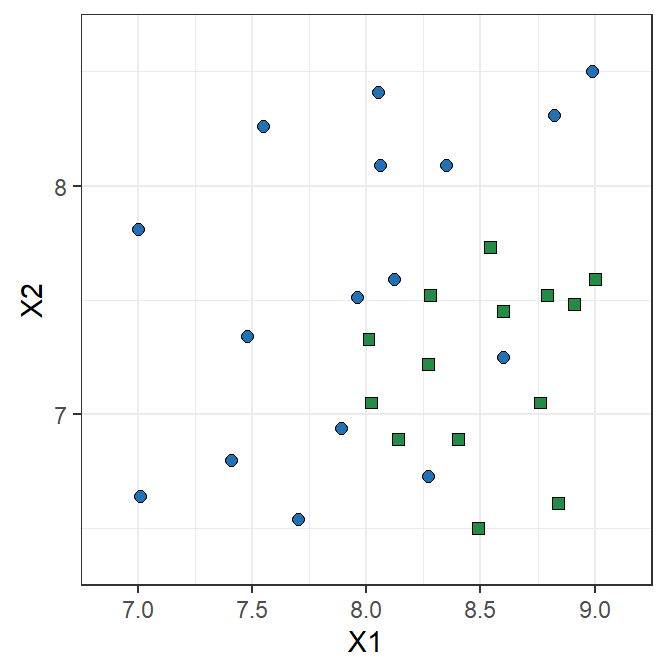
Toy example: Logistic Regression
\ln\left(\frac{\mathbb{P}(Y=1|X)}{1-\mathbb{P}(Y=1|X)}\right) = 13.671 - 4.136 X_1 + 2.803 X_2
| X1 | X2 | log-odds | P(Y=1|X) | prediction |
|---|---|---|---|---|
| 7.0 | 8.0 | 7.14 | 0.9992 | blue |
| 8.0 | 7.5 | 1.61 | 0.8328 | blue |
| 8.0 | 7.0 | 0.20 | 0.5508 | blue |
| 8.5 | 7.5 | -0.46 | 0.3864 | green |
| 9.0 | 7.0 | -3.93 | 0.0192 | green |
Note: the prediction is 1 (“blue”) if \mathbb{P}[Y=1|\mathrm{X}]>0.5.
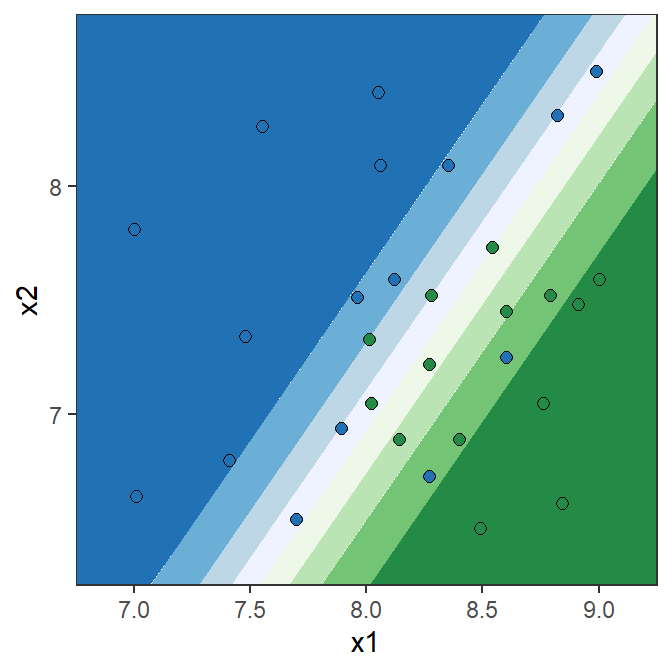
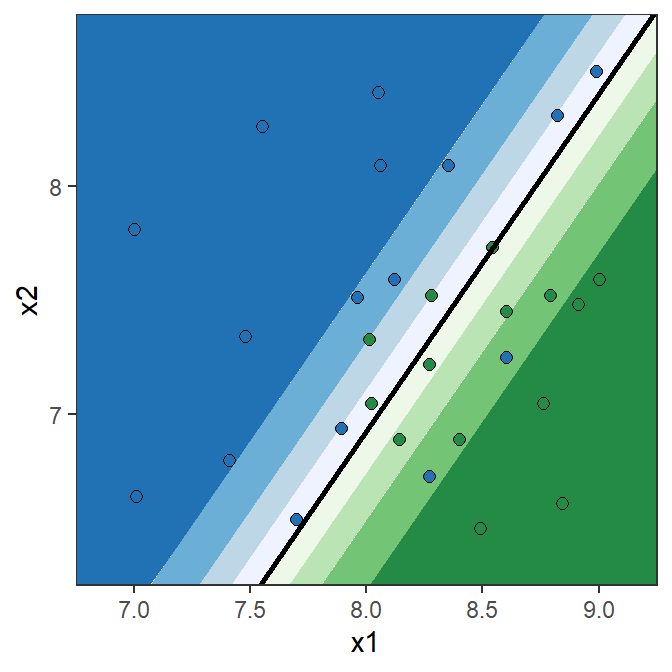
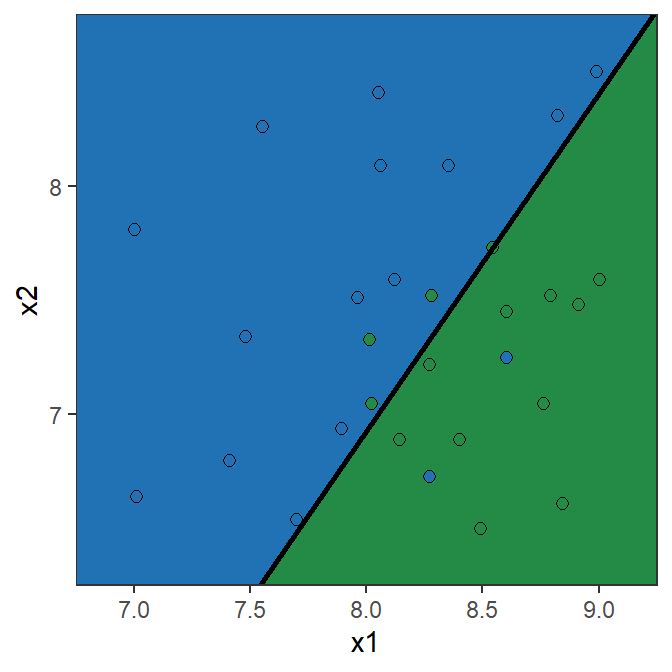
Error rate and accuracy in classification problems
- Recall the (training) error rate is simply \text{error rate}=\frac{1}{n}\sum_{i=1}^n I(y_i\neq \hat{y}_i)
- In our toy example (with a 50% threshold), \text{training error rate}= \frac{6}{30} = 0.2
- We call accuracy “1-\text{error rate}”; this represents the proportion of correct predictions.
- Question for a Champion: is the error rate enough to evaluate the performance of a model?
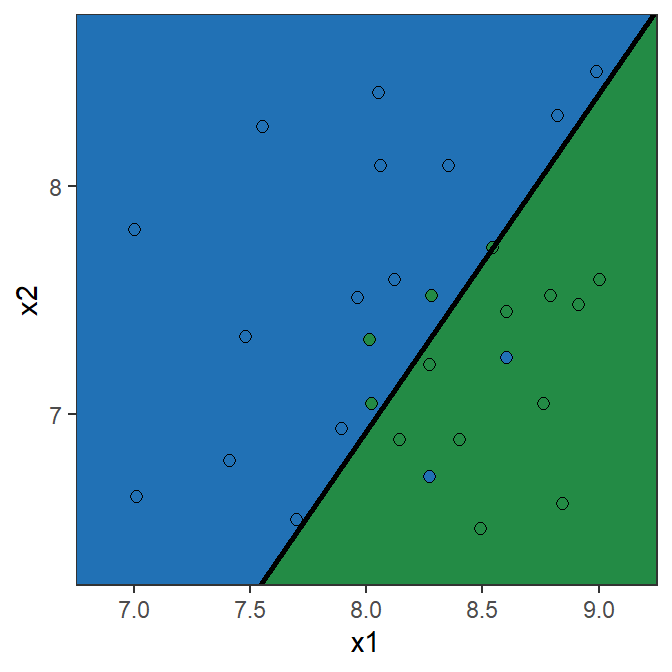
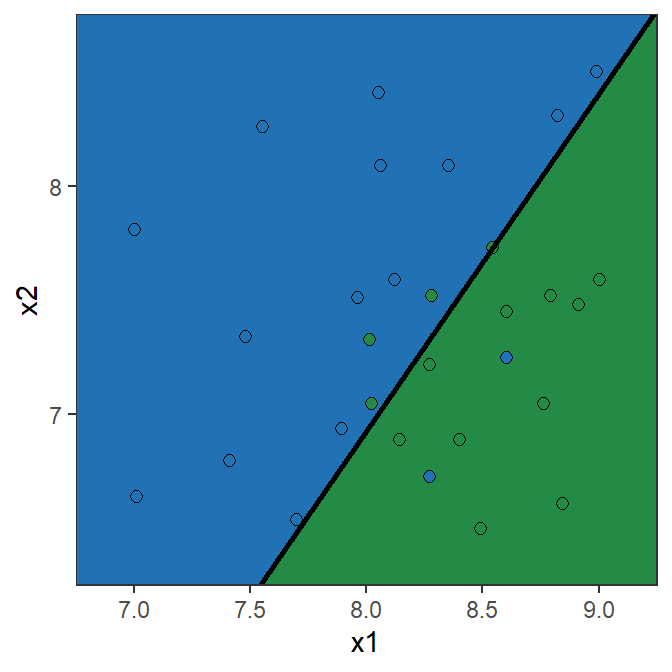
There are two types or errors we can make!

Confusion matrix: Toy example (50% Threshold)
Confusion matrix
Y=0 Y=1 Total \hat{Y}=0 10 2 12 \hat{Y}=1 4 14 18 Total 14 16 30 \text{Recall} = \frac{14}{16}=0.875
\text{Specificity} = \frac{10}{14}=0.714
\text{Precision} = \frac{14}{18}=0.778
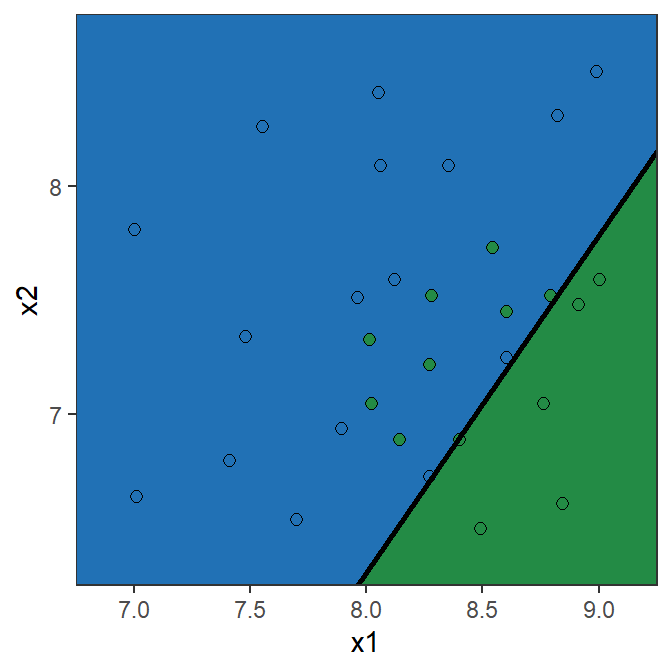
Confusion matrix: Toy example (15% Threshold)
Confusion matrix
Y=0 Y=1 Total \hat{Y}=0 6 0 6 \hat{Y}=1 8 16 24 Total 14 16 30 \text{Recall} = \frac{16}{16}=1
\text{Specificity} = \frac{6}{14}=0.429
\text{Precision} = \frac{16}{24}=0.667
The Bikeshare dataset - Discussion
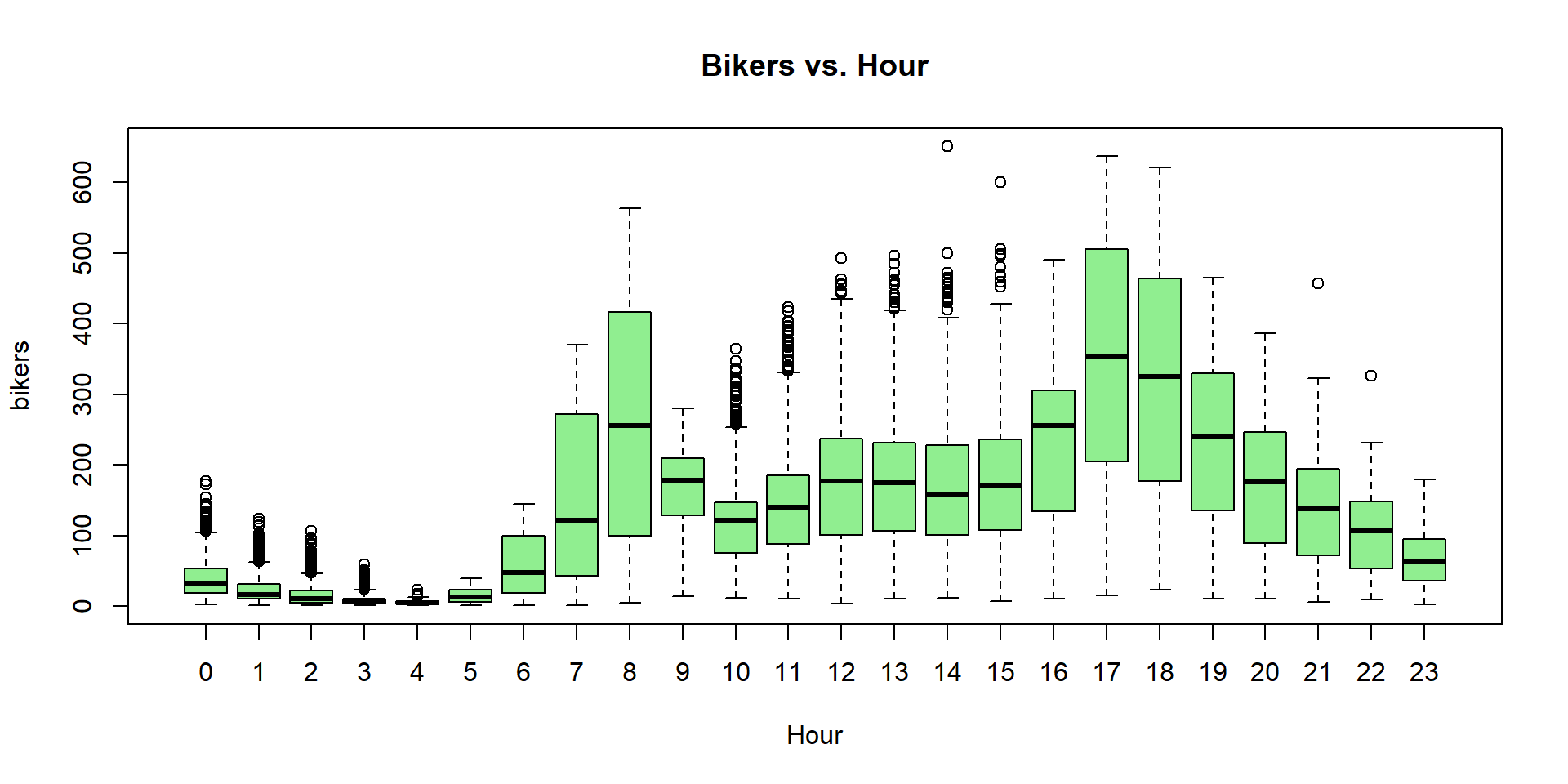
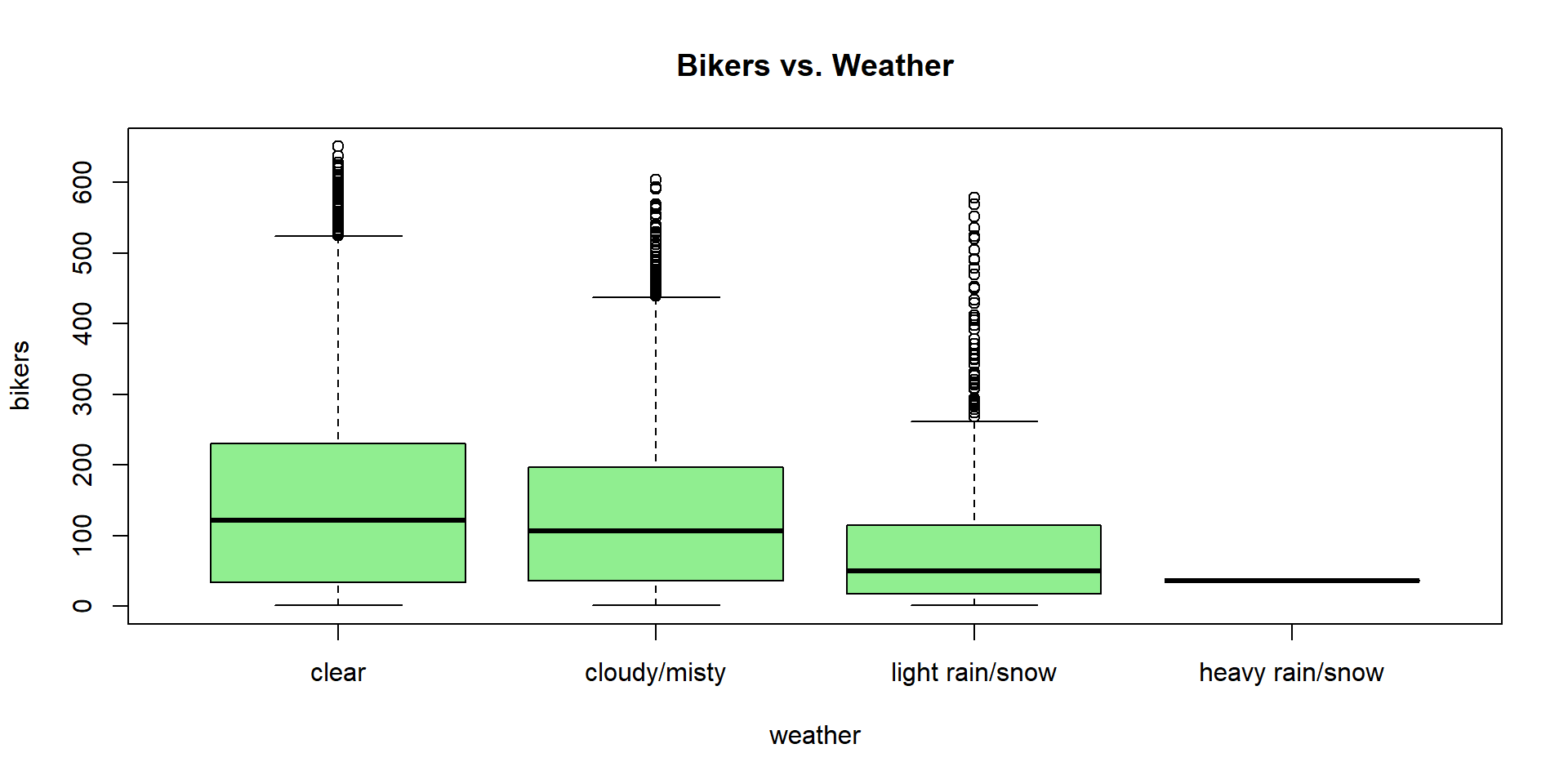
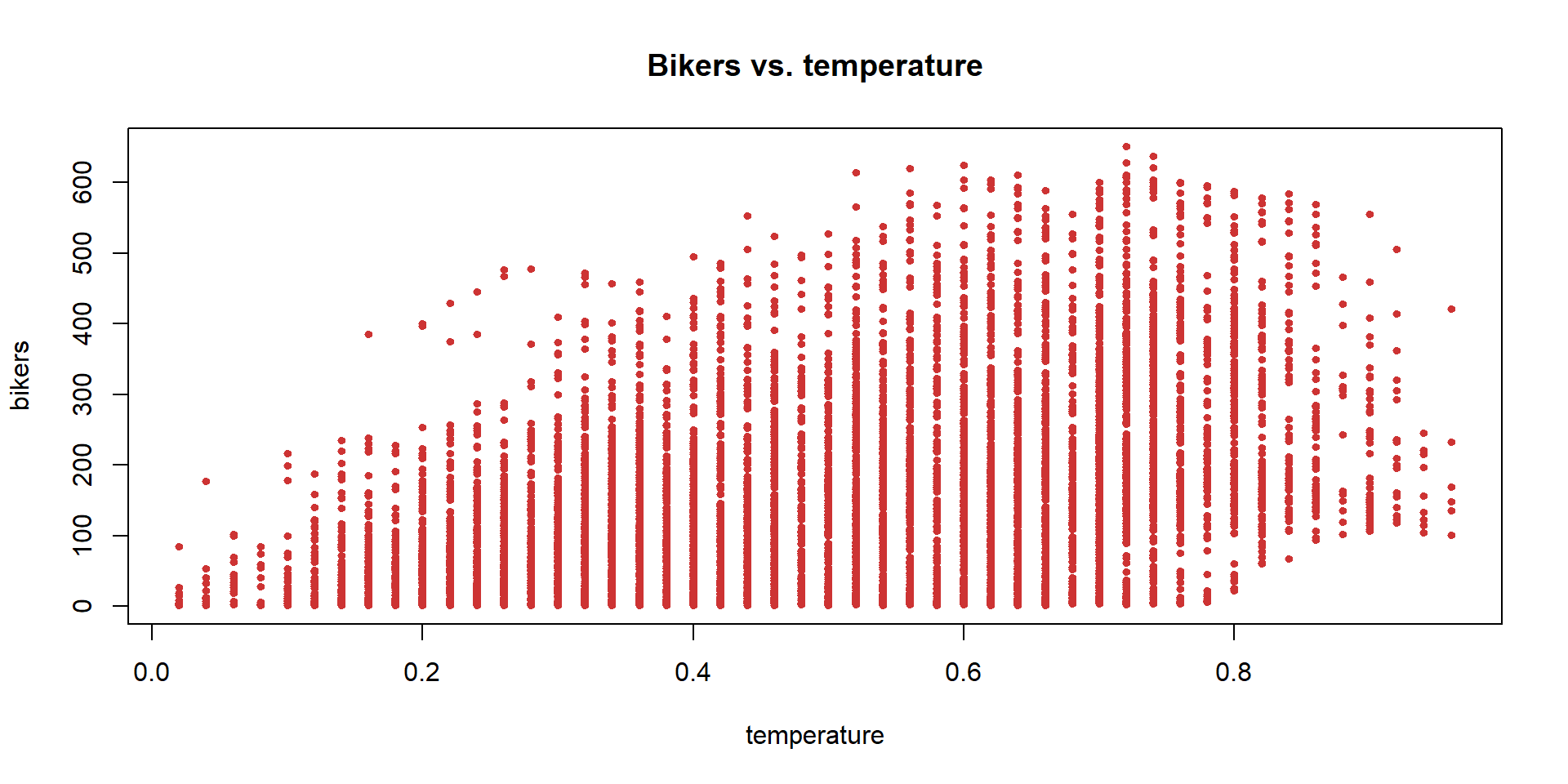
Poisson regression - Bikeshare dataset
plot(x = 1:12, y = c(0, glmBikeshare$coefficients[7:17]), type = 'o',
xlab = "month", ylab = "coefficient", xaxt = "n")
axis(1, at=1:12, labels=substr(month.name, 1, 1))
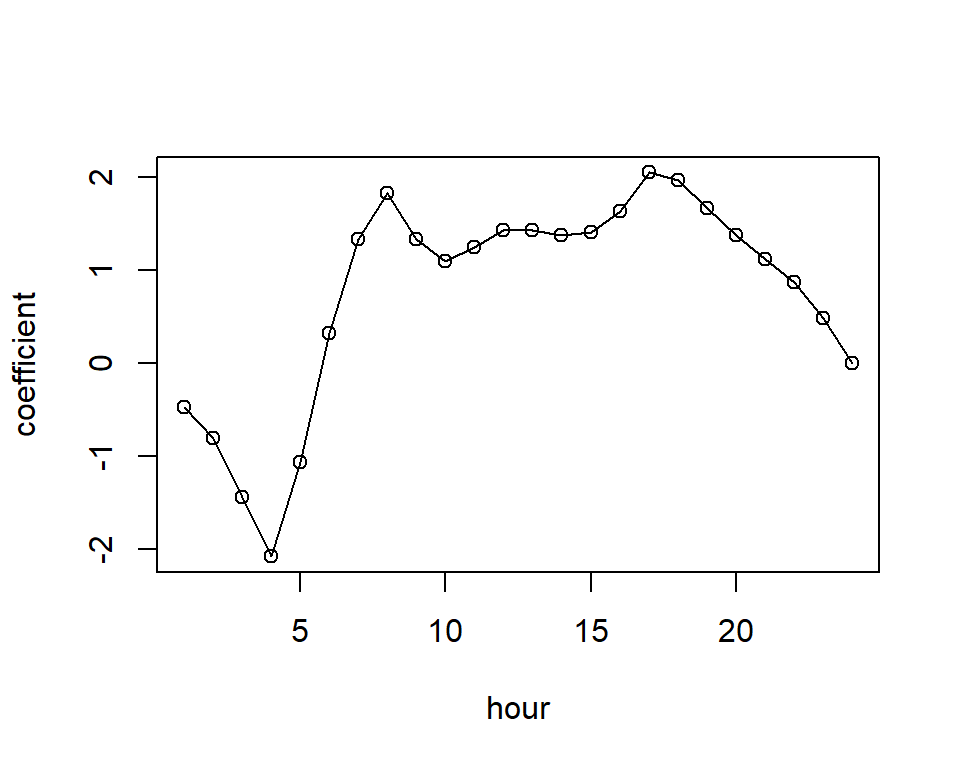
plot(x = 1:24, y = c(glmBikeshare$coefficients[18:40], 0), type = 'o',
xlab = "hour", ylab = "coefficient")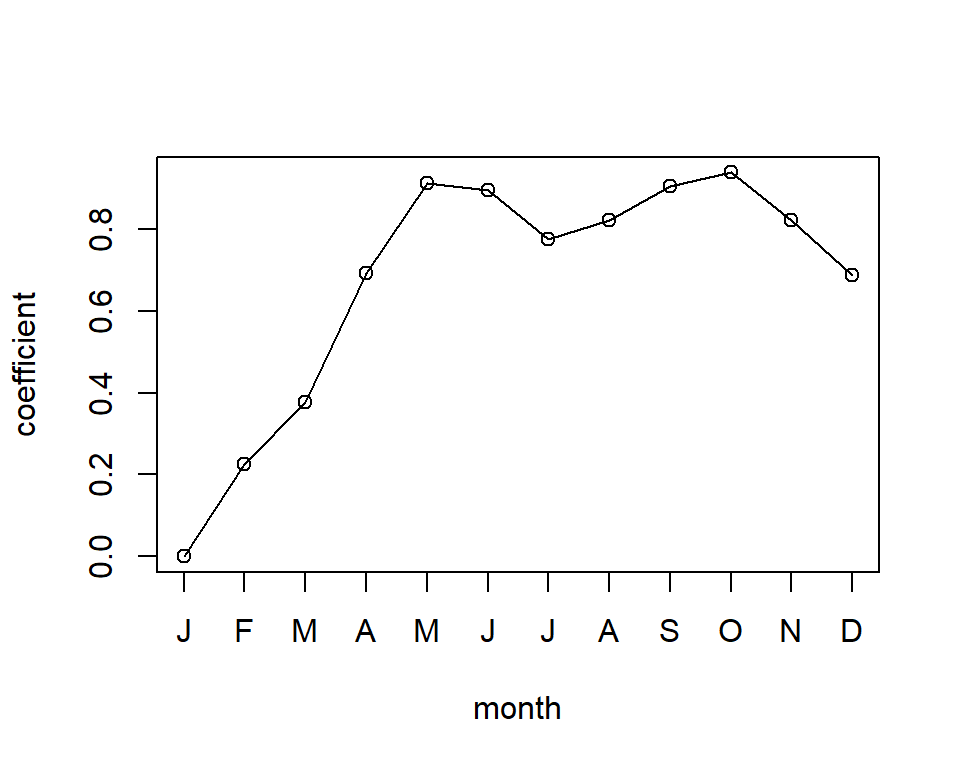
Comments about logistic regression