Imagine you had dataset with 157,209 rows and one covariate column was ‘date of birth’. There were 27,485 unique values for the date of birth column. You make a linear regression with the date of birth as an input, and treat it as a categorical variable (the default behaviour for text data in R).
R would make a design matrix of size 157,209 \times 27,485. This has 4,320,889,365 numbers in it. Each number is stored as 8 bytes, so the matrix is roughly
34,000,000,000 \text{ bytes}
= 34,000,000 \text{ KB}
= 34,000 \text{ MB}
= 34 \text{ GB}.
Question: How do we avoid this situation of crashing our computer with an ‘out of memory’ error?
Solution: Don’t train on the date of birth — at least, not as a categorical variable. Turn it into a numerical variable, e.g. age. If the date column were not ‘date of birth’, maybe calculate the number of days since some reference date, or split into day, month, year columns.
Step 1: Make a linear prediction \beta_0 + \beta_1 x_1 + \dots + \beta_p x_p , \quad \text{a.k.a.} \quad \langle \boldsymbol{\beta}, \boldsymbol{x} \rangle.
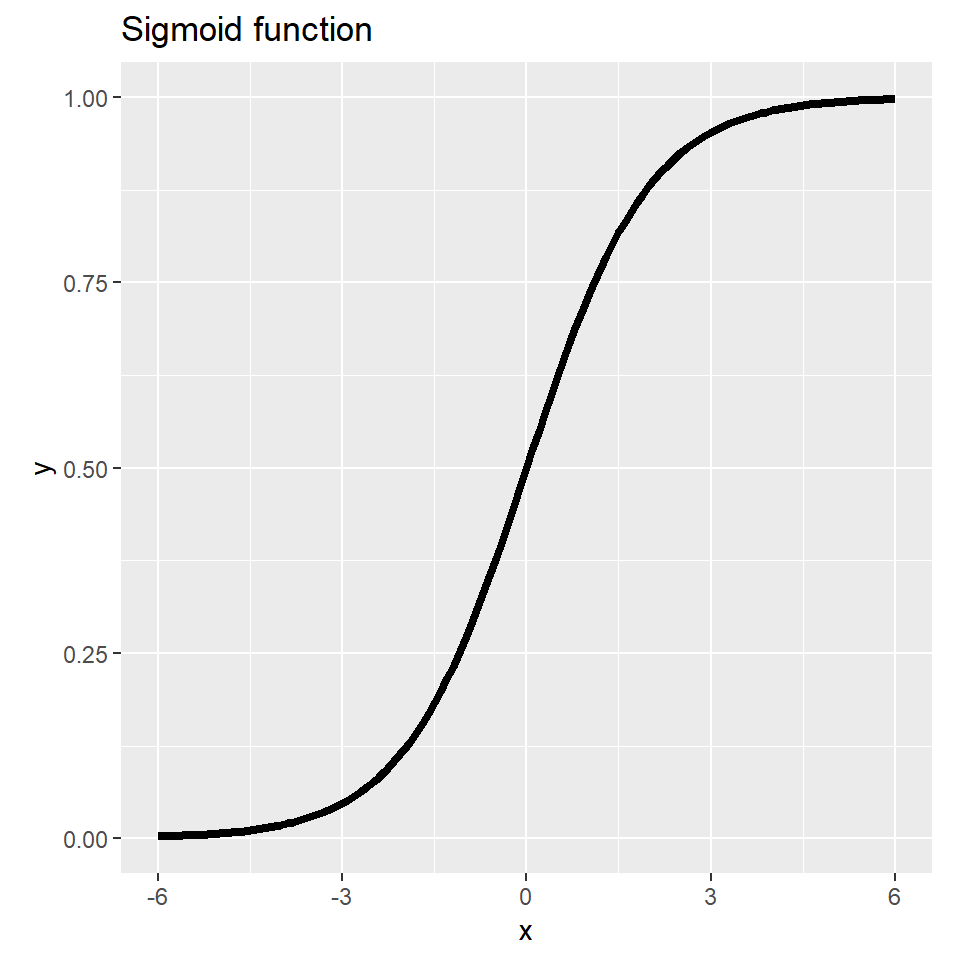
Step 2: Shove it through some function to make it a probability \sigma(\langle \boldsymbol{\beta}, \boldsymbol{x} \rangle) Interpret that as being the probability of the positive class.
Step 3: Make a decision based on that probability. E.g., if the probability is greater than 0.5, predict the positive class.
The word “accuracy” is used often used loosely when discussing models, particularly regression models. In the context of classification it has this specific meaning.
Poisson regression
Scenario: use population density to predict the daily count ofgun violence incidents
Step 1: Make a linear prediction \beta_0 + \beta_1 x_1 + \dots + \beta_p x_p , \quad \text{a.k.a.} \quad \langle \boldsymbol{\beta}, \boldsymbol{x} \rangle.
Step 2: Shove it through some function to make it positive \exp(\langle \boldsymbol{\beta}, \boldsymbol{x} \rangle) Interpret that as being the expected count.
Predict the mean of a Poisson distribution
Scenario: use population density to predict the daily count ofgun violence incidents
guns <-data.frame(density =c(10, 15, 12, 18))incidents <-c(155, 208, 116, 301)model <-glm(incidents ~ density, data = guns, family = poisson)summary(model)$coefficients
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.7803729 0.17881503 21.141248 3.321765e-99
density 0.1048546 0.01190339 8.808802 1.264908e-18
predict(model, newdata = guns, type ="link")
1 2 3 4
4.828919 5.353192 5.038628 5.667756
predict(model, newdata = guns, type ="response")
1 2 3 4
125.0757 211.2817 154.2583 289.3844
Splines (Week 7)
Trees (Week 8)
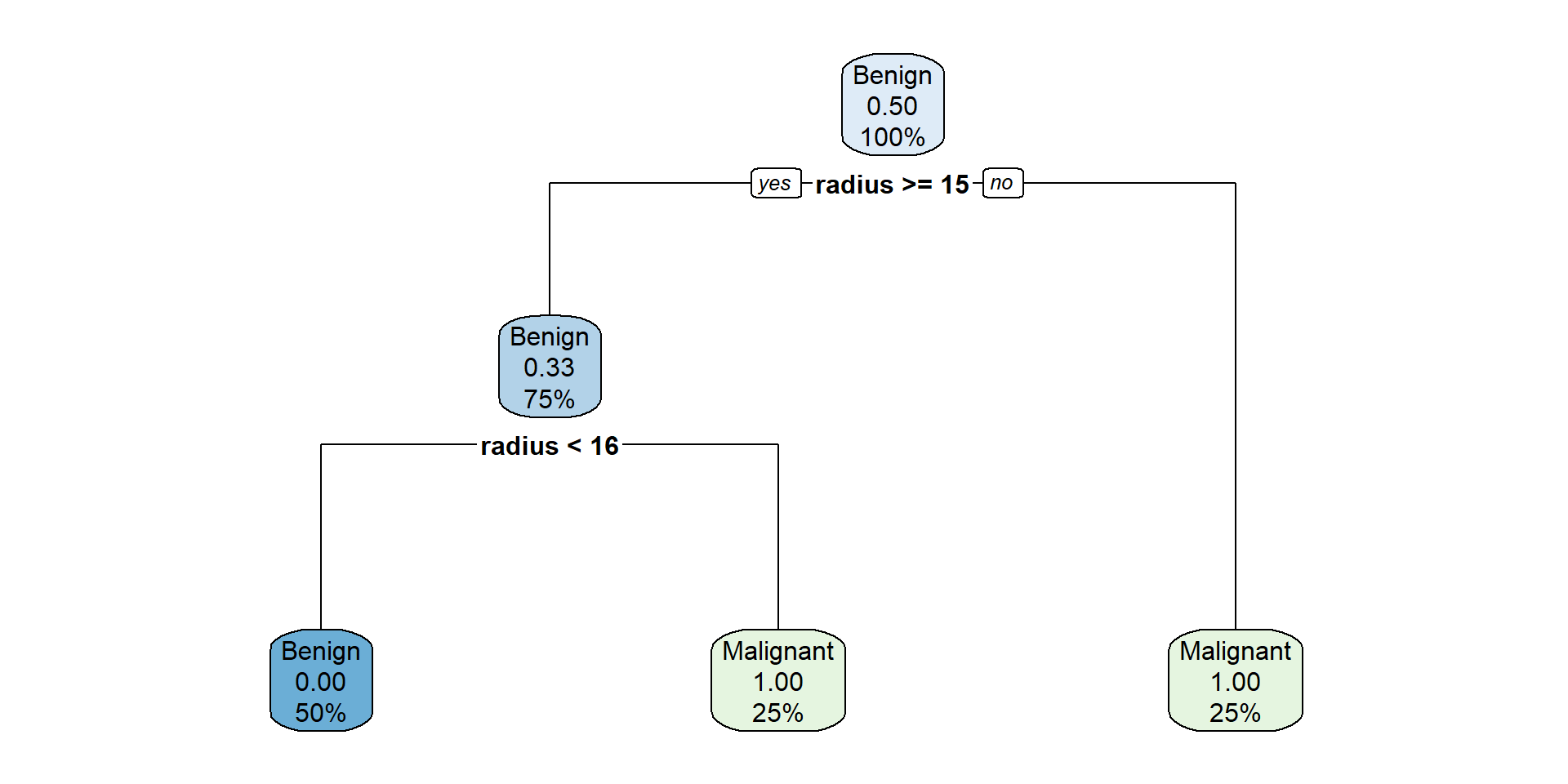
model <-rpart(tumour ~ radius + age, data = df, control =rpart.control(minsplit =2))rpart.plot(model)
Glassdoor Dataset
Lecture Outline
Linear Regression Recap
Generalised Linear Models Recap
Glassdoor Dataset
Statistical Model Evaluation
Validation Set Approach
k-Fold Cross-Validation
Leave-One-Out Cross-Validation
Regularisation
Regularisation Plots
Regularisation Demos
Ridge and Lasso Intuition
Glassdoor Job Reviews
“This large dataset contains job descriptions and rankings among various criteria such as work-life balance, income, culture, etc. The data covers the various industries in the UK. Great dataset for multidimensional sentiment analysis.”
Original dataset is 300 MB, so I just took a subset of it. Focused on firms that have the word “University” in their name.
Dall-E 2 rendition of this dataset
The columns
Rankings are 1–5:
overall_rating: rating for the job (target)
work_life_balance: sub-rating: work-life balance
culture_values: sub-rating: culture
diversity_inclusion: sub-rating: diversity and inclusion
career_opp: sub-rating: career opportunities
comp_benefits: sub-rating: compensation and benefits
senior_mgmt: sub-rating: senior management
Last two are coded: v - Positive, r - Mild, x - Negative, o - No opinion
firm date_review job_title current
Length:18358 Length:18358 Length:18358 Length:18358
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
location overall_rating work_life_balance culture_values
Length:18358 Min. :1.000 Min. :1.00 Min. :1.000
Class :character 1st Qu.:4.000 1st Qu.:3.00 1st Qu.:3.000
Mode :character Median :4.000 Median :4.00 Median :4.000
Mean :4.136 Mean :3.89 Mean :3.962
3rd Qu.:5.000 3rd Qu.:5.00 3rd Qu.:5.000
Max. :5.000 Max. :5.00 Max. :5.000
NA's :5316 NA's :5782
diversity_inclusion career_opp comp_benefits senior_mgmt
Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000
1st Qu.:4.000 1st Qu.:3.000 1st Qu.:3.000 1st Qu.:3.000
Median :5.000 Median :4.000 Median :4.000 Median :4.000
Mean :4.146 Mean :3.649 Mean :3.542 Mean :3.484
3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:5.000
Max. :5.000 Max. :5.000 Max. :5.000 Max. :5.000
NA's :15448 NA's :5226 NA's :5452 NA's :5641
recommend ceo_approv outlook headline
Length:18358 Length:18358 Length:18358 Length:18358
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
pros cons
Length:18358 Length:18358
Class :character Class :character
Mode :character Mode :character
Anonymous Employee
3817 1581
Student PhD Student
992 940
Research Assistant Research Associate
592 577
Postdoctoral Research Associate Student Ambassador
325 317
Lecturer Research Fellow
262 216
Look at the textual data
# Print a random sample of 'pros' and 'cons'set.seed(123)sample(df_uni$pros, 5)
[1] "Good Staff and Work Environment, Cheap cost of living."
[2] "Amazing people, depts vary. Some research groups are disfunctional, some are amazing places. The one I am is amazing."
[3] "Amazing University. As well as working within the area I was assigned it was encouraged that interns seek out people from other parts of the company in order to learn more about the different areas within RR.\n- Supportive Team\n- Loads of Feedback\n- Interesting Projects"
[4] "It was a great learning experience among many experienced professionals in the health care industry."
[5] "Great city, great campus, good relationships between academic and administrative/technical staff, strong NSS results and a desire to maintain the student experience and grow the high quality research output."
sample(df_uni$cons, 5)
[1] "poor management and divide and rule tactics have driven most staff to leave their jobs"
[2] "Not much work to do which result in limited experience."
[3] "Not enough pay for the work you do in certain departments"
[4] "long job hours sometimes go past 40hrs a week"
[5] "Bureaucratic. There are support mechanisms but sometimes, needs lots of approval. IT is also slow. Needs better balance in workloads."
Change some bizarre coding scheme
Two columns had: v - Positive, r - Mild, x - Negative, o - No opinion
The AIC/BIC definitions are those specific to Linear Regression, but those criterias are defined much more generally.
For the Glassdoor models
Model 1
AIC(model_subrankings)
[1] 21646.59
BIC(model_subrankings)
[1] 21698.41
summary(model_subrankings)$adj.r.squared
[1] 0.6871576
Model 2
AIC(model_recommend)
[1] 28592.3
BIC(model_recommend)
[1] 28644.12
summary(model_recommend)$adj.r.squared
[1] 0.4452108
Which is the better model (according to this ‘indirect’ approach)?
Validation Set Approach
Lecture Outline
Linear Regression Recap
Generalised Linear Models Recap
Glassdoor Dataset
Statistical Model Evaluation
Validation Set Approach
k-Fold Cross-Validation
Leave-One-Out Cross-Validation
Regularisation
Regularisation Plots
Regularisation Demos
Ridge and Lasso Intuition
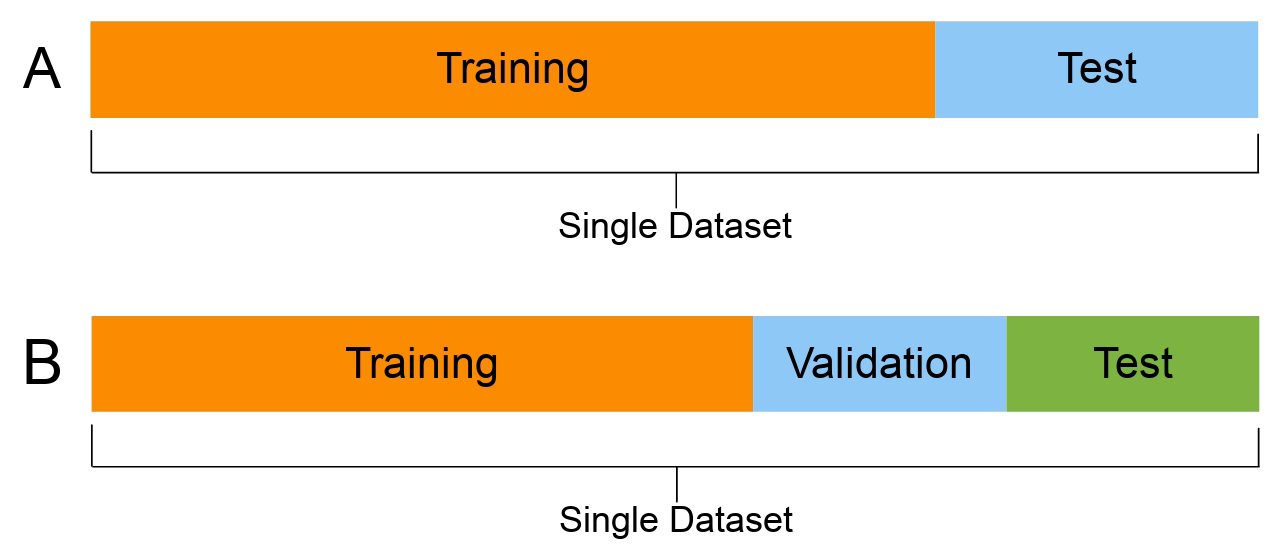
The ML approach
Just make predictions on new data.
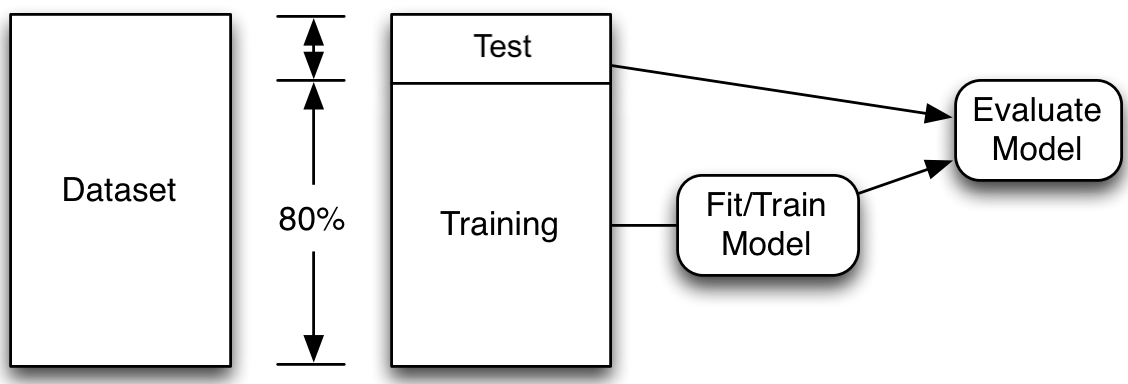
Set aside a fraction after shuffling.
Illustration of a typical training/test split.
Note
The model’s metrics on the test set are the test set error. Note, there is also the term test error which is the model’s expected (or “theoretical”) error on unseen data. So, test set error is an estimate of the test error.
The validation set approach
Splitting the data.
For each model, fit it to the training set.
Compute the error for each model on the validation set.
Select the model with the lowest validation error.
Compute the error of the final model on the test set.
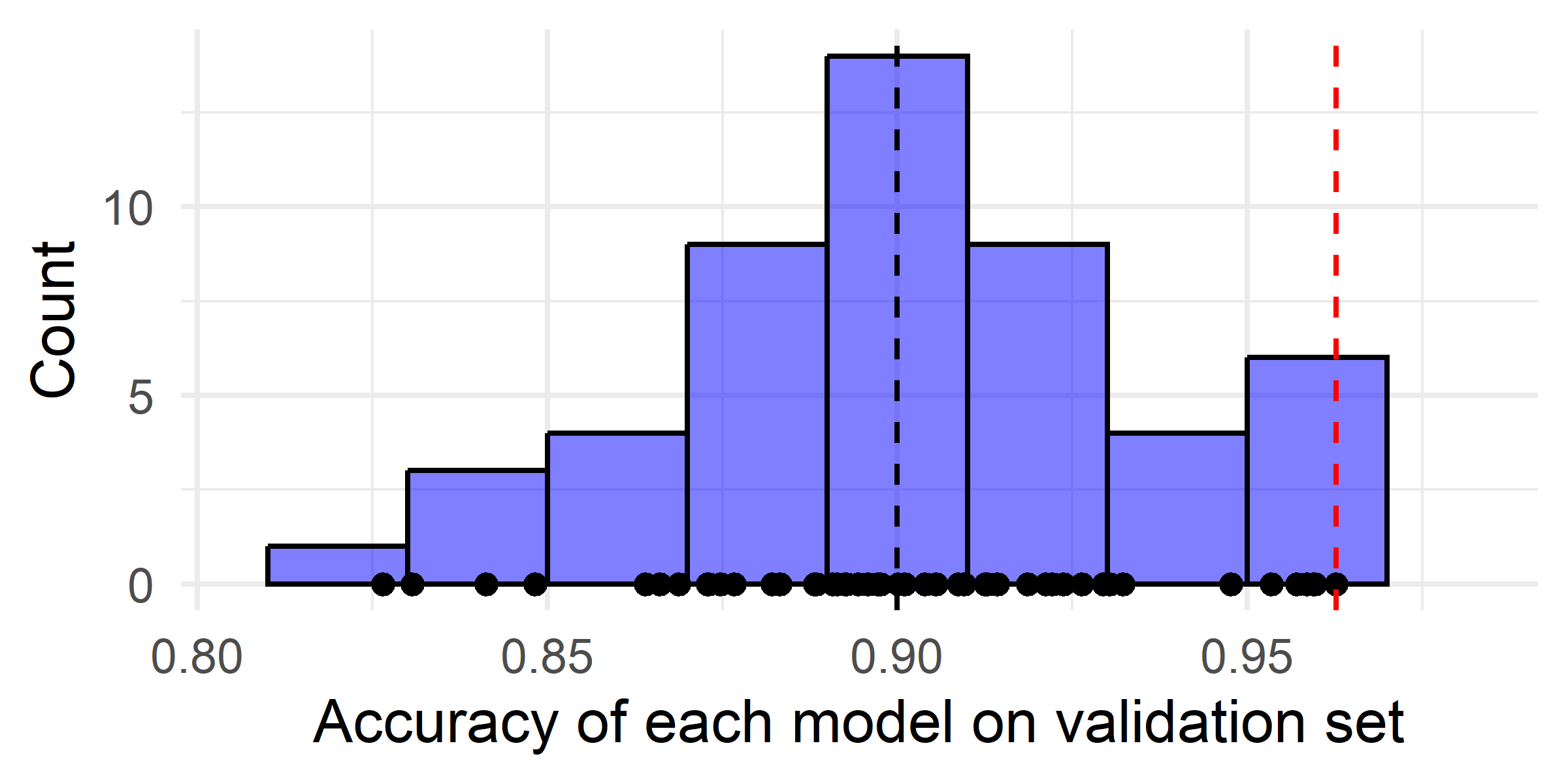
Why shuffle the data?
Let’s create a toy dataset where the target values are separated.
# First extract the test dataset:set.seed(1)test_index <-sample(1:nrow(df_uni), 0.2*nrow(df_uni))test <- df_uni[test_index, ]train_val <- df_uni[-test_index, ]# Then split the rest into validation and training sets:val_index <-sample(1:nrow(train_val), 0.25*nrow(train_val))val <- train_val[val_index, ]train <- train_val[-val_index, ]
dim(train)
[1] 7275 18
dim(val)
[1] 2425 18
dim(test)
[1] 2424 18
Remember, models tend to improve with more data (not always!).
Lastly, if you want the best possible model, you can retrain on the entire dataset:
model_subrankings_all <-update(model_subrankings, data = df_uni)
But we have no unseen data to test this on!
Validation Set Approach
“In statistics, sometimes we only use a single data set. To still be able to evaluate the performance of the developed prediction model on the same data, sophisticated methods have developed over a long period of time and are still in use in some parts of the statistics community. These methods account for the fact that the model saw the data during fitting and applied corrections to account for that. These methods include, for example, the Akaike Information Criterion (AIC) or the Bayesian Information Criterion (BIC). Don’t get confused. If you have a validation set, you don’t need these methods.”
k-Fold Cross-Validation
Lecture Outline
Linear Regression Recap
Generalised Linear Models Recap
Glassdoor Dataset
Statistical Model Evaluation
Validation Set Approach
k-Fold Cross-Validation
Leave-One-Out Cross-Validation
Regularisation
Regularisation Plots
Regularisation Demos
Ridge and Lasso Intuition
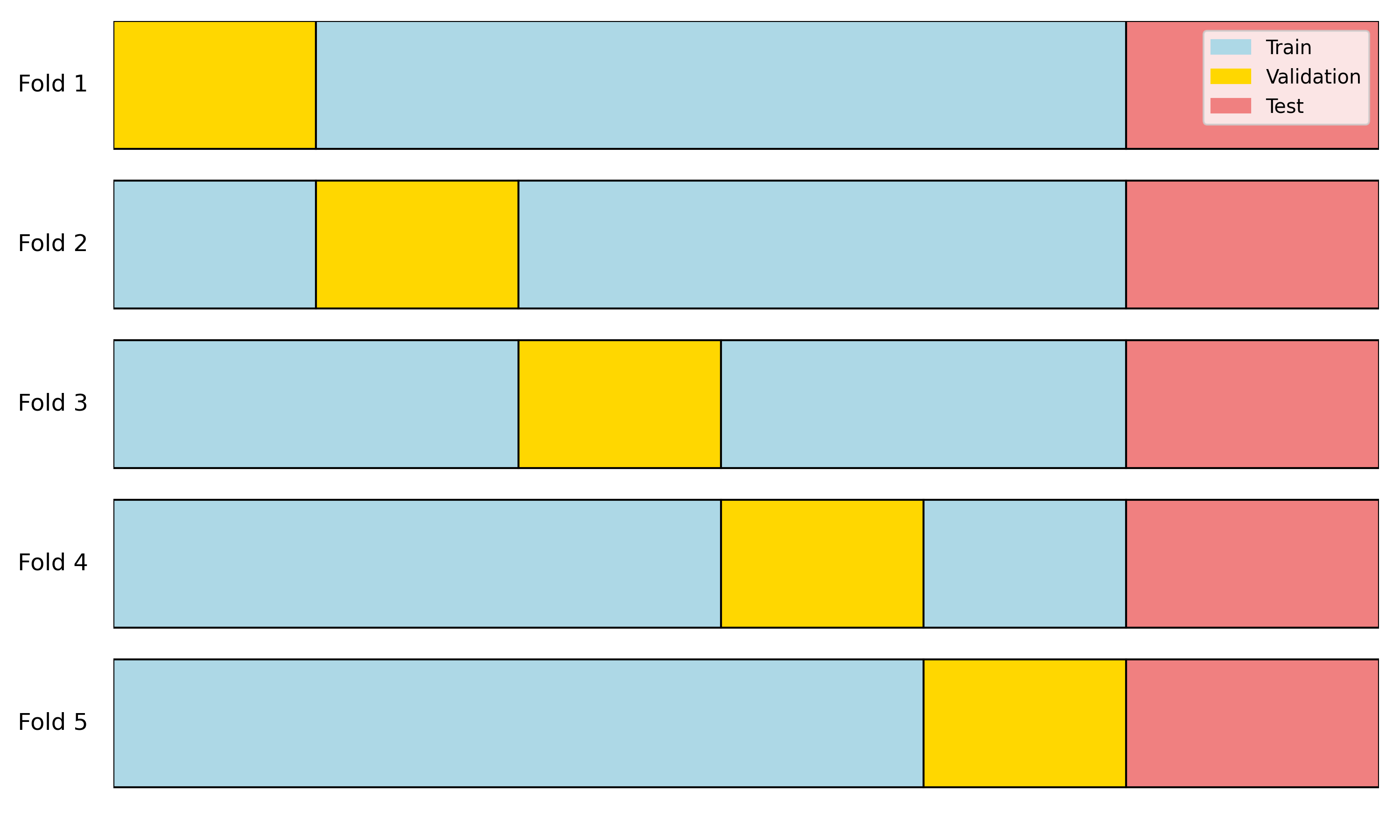
Illustration
Illustration of 5-fold cross-validation.
Idea
Randomly divide the set of observations into K groups (“folds”) of about equal size
the k^\text{th} fold is treated as a validation set
the remaining K-1 folds make up the training set
Repeat K times, yielding K estimates of the test error \mathrm{CV}_{(K)} = \frac{1}{K} \sum_{k=1}^{K} \mathrm{MSE}_k
In practice, K = 5 or K = 10
LOOCV is a special case where K = n
Simulated Examples
Cross-Validation
set.seed(123)train_val <-rbind(train, val)train_val_shuffle <- train_val[sample(1:nrow(train_val)), ]k <-5fold_size <-floor(nrow(train_val) / k)mse_subrankings <-numeric(k)mse_recommend <-numeric(k)for (i in1:k) { val_indices <- ((i -1) * fold_size +1):(i * fold_size) val <- train_val_shuffle[val_indices, ] train <- train_val_shuffle[-val_indices, ] model_subrankings <-lm(overall_rating ~ work_life_balance + culture_values + career_opp + comp_benefits + senior_mgmt, data = train) model_recommend <-lm(overall_rating ~ recommend + ceo_approv, data = train) mse_subrankings[i] <-mean((predict(model_subrankings, newdata = val) - val$overall_rating)^2) mse_recommend[i] <-mean((predict(model_recommend, newdata = val) - val$overall_rating)^2)}mse_subrankings # MSEs for the 5 folds of model "subrankings"
Call:
glm(formula = overall_rating ~ recommend + ceo_approv, data = train_val)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.05949 0.01757 231.037 < 2e-16 ***
recommendPositive 0.33592 0.02415 13.911 < 2e-16 ***
recommendNegative -1.50366 0.03262 -46.097 < 2e-16 ***
ceo_approvPositive 0.17313 0.02291 7.557 4.48e-14 ***
ceo_approvMild -0.18049 0.02298 -7.853 4.50e-15 ***
ceo_approvNegative -0.56915 0.03921 -14.516 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for gaussian family taken to be 0.6159165)
Null deviance: 10597.8 on 9699 degrees of freedom
Residual deviance: 5970.7 on 9694 degrees of freedom
AIC: 22834
Number of Fisher Scoring iterations: 2
Using cv.glm
No need to write your own loop, you can use a function like cv.glm:
library(boot)set.seed(123)# Fit the models as 'glm's firstmodel_subrankings <-glm(overall_rating ~ work_life_balance + culture_values + career_opp + comp_benefits + senior_mgmt, data = train_val)model_recommend <-glm(overall_rating ~ recommend + ceo_approv, data = train_val)# Pass them to 'cv.glm'cv_subrankings <-cv.glm(train_val, model_subrankings, K =5)cv_recommend <-cv.glm(train_val, model_recommend, K =5)(cv_mse_subrankings <- cv_subrankings$delta[1])
[1] 0.3447204
(cv_mse_recommend <- cv_recommend$delta[1])
[1] 0.6168303
Leave-One-Out Cross-Validation
Lecture Outline
Linear Regression Recap
Generalised Linear Models Recap
Glassdoor Dataset
Statistical Model Evaluation
Validation Set Approach
k-Fold Cross-Validation
Leave-One-Out Cross-Validation
Regularisation
Regularisation Plots
Regularisation Demos
Ridge and Lasso Intuition
LOOCV: Idea
Split the set of observations into two parts:
a single observation(x_i, y_i) for the validation set
the remaining observations make up the training set: \{(x_1, y_1), \ldots, (x_{i-1}, y_{i-1}), (x_{i+1}, y_{i+1}), \ldots, (x_{n}, y_{n})\}
Fit the model on the n-1 training observations
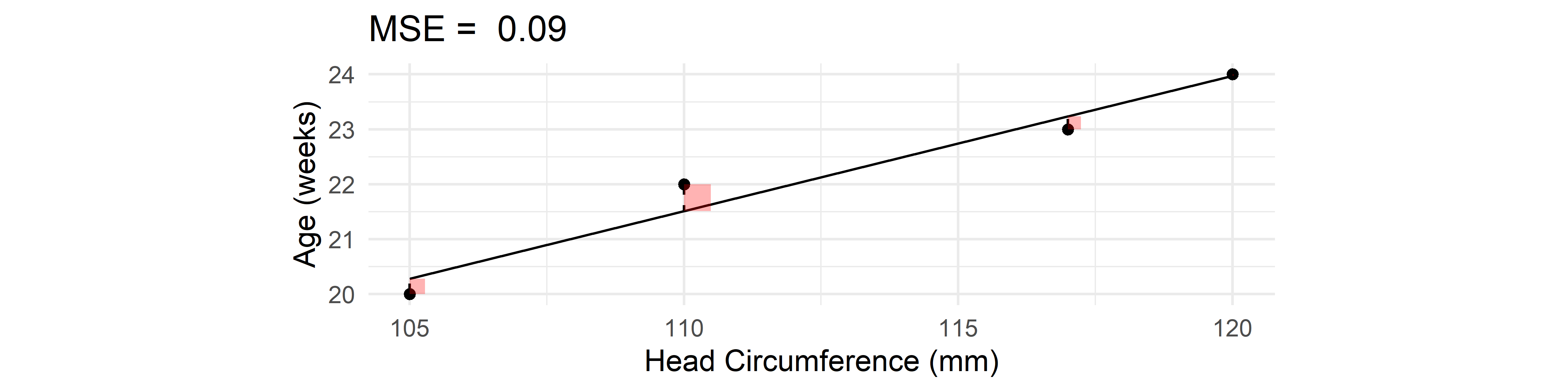
Predict \hat{y}_i, using the fitted model, and compute the validation MSE:
\mathrm{MSE}_i = (y_i - \hat{y}_i)^2
this is an approximately unbiased estimate of the test error
Repeat the procedure n times
The resulting LOOCV estimate of the test error is: \mathrm{CV}_{(n)} = \frac{1}{n} \sum_{i=1}^{n} \mathrm{MSE}_i
Validation set vs LOOCV - Discussion
Discuss how you expect LOOCV to perform relative to the Validation Set approach. Any obvious pros and/or cons?
Pros:
We make “maximal use” of the data: each observation is in turn treated as a training data point (n-1 times) and as a validation data point.
With LOOCV, we train on many more observations (n-1) so the estimate of the test set error is (almost) unbiased.
LOOCV does not involve randomisation: we estimate the test error on alln “folds” of size 1, and average the result.
Cons:
It is computationally expensive: we train n times as many models as before!
The \mathrm{MSE}_i are highly correlated (as training sets are almost identical). Because of that, “the test error estimate resulting from LOOCV tends to have higher variance than does the test error estimate resulting from k-fold CV” (James et al., 2021).
LOOCV for least square linear models
For linear (or polynomial) regression, LOOCV is extremely cheap to compute: \text{CV}_{(n)} = \frac{1}{n} \sum_{i=1}^n \left(\frac{y_i-\hat{y}_i}{1-h_i}\right)^2
where
\hat{y}_i is the original least squares fit
h_i is the leverage defined in Chapter 3 (Module 2)
This cute simplification is not available “in general”.
Harry Potter dataset
(movies <-read.csv("Movies.csv"))
# A tibble: 8 × 6
Movie.ID Movie.Title Release.Year Runtime Budget Box.Office
<int> <chr> <int> <int> <chr> <chr>
1 1 Harry Potter and the Philosop… 2001 152 "$125… "$1,002,0…
2 2 Harry Potter and the Chamber … 2002 161 "$100… "$880,300…
3 3 Harry Potter and the Prisoner… 2004 142 "$130… "$796,700…
4 4 Harry Potter and the Goblet o… 2005 157 "$150… "$896,400…
5 5 Harry Potter and the Order of… 2007 138 "$150… "$942,000…
6 6 Harry Potter and the Half-Blo… 2009 153 "$250… "$943,200…
7 7 Harry Potter and the Deathly … 2010 146 "$200… "$976,900…
8 8 Harry Potter and the Deathly … 2011 130 "$250… "$1,342,0…
# Clean the dataset and convert relevant columns to numerical formatmovies$Budget <-as.numeric(gsub("[\\$,]", "", movies$Budget))movies$Box.Office <-as.numeric(gsub("[\\$,]", "", movies$Box.Office))
# Grab just one movie as a test setset.seed(1)test_index <-sample(1:nrow(movies), 1)train_val <- movies[-test_index, ](test <- movies[test_index, ])
# A tibble: 1 × 6
Movie.ID Movie.Title Release.Year Runtime Budget Box.Office
<int> <chr> <int> <int> <dbl> <dbl>
1 1 Harry Potter and the Philosop… 2001 152 1.25e8 1002000000
LOOCV for the Harry Potter dataset
model_year <-glm(Box.Office ~ Budget + Release.Year, data = train_val)model_runtime <-glm(Box.Office ~ Budget + Runtime, data = train_val)cv_year <-cv.glm(train_val, model_year) # cv.glm defaults to LOOCVcv_runtime <-cv.glm(train_val, model_runtime)
cv_year$delta[1]
[1] 5.76601e+16
cv_runtime$delta[1]
[1] 4.987983e+16
# Test error for the runtime modeltest_pred_runtime <-predict(model_runtime, newdata = test)(mean((test$Box.Office - test_pred_runtime)^2))
# Load datasetlibrary(mlbench)data(BostonHousing)# Split the data into training and test setsset.seed(123)train_index <-sample(nrow(BostonHousing),0.8*nrow(BostonHousing))train <- BostonHousing[train_index, ]test <- BostonHousing[-train_index, ]# Fit a linear regression modellm_model <-lm(medv ~ ., data = train)# Calculate the training and test errorstrain_pred <-predict(lm_model, newdata = train)train_error <-mean((train_pred - train$medv)^2)lm_model <-lm(medv ~ ., data = test)test_pred <-predict(lm_model, newdata = test)test_error <-mean((test_pred - test$medv)^2)# Print the training and test errorscat("Training Error (MSE):", train_error, "\n")
Training Error (MSE): 21.60875
cat("Test Error (MSE):", test_error, "\n")
Test Error (MSE): 20.26994
3a) Which do you expect to be lower on average, the training loss or the test loss? Why?
3b) Describe why, in this case, the test error is less than the training error.
Model has been re-trained on the test set for the purpose of computing the “test error”… this is illegal!
Regularisation
Lecture Outline
Linear Regression Recap
Generalised Linear Models Recap
Glassdoor Dataset
Statistical Model Evaluation
Validation Set Approach
k-Fold Cross-Validation
Leave-One-Out Cross-Validation
Regularisation
Regularisation Plots
Regularisation Demos
Ridge and Lasso Intuition
Tall data vs wide data
A tall dataset (n \gg p)
Traditional linear regression methods
A wide dataset (p \gg n)
Traditional methods break, regularisation methods can help
Linear Models with p > n
If p > n, \text{R} will just fit the first n parameters and give NA for the rest.
Call:
lm(formula = overall_rating ~ work_life_balance + culture_values +
career_opp + comp_benefits + senior_mgmt, data = first_few_rows)
Residuals:
ALL 3 residuals are 0: no residual degrees of freedom!
Coefficients: (3 not defined because of singularities)
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.6667 NaN NaN NaN
work_life_balance -0.3333 NaN NaN NaN
culture_values 0.6667 NaN NaN NaN
career_opp NA NA NA NA
comp_benefits NA NA NA NA
senior_mgmt NA NA NA NA
Residual standard error: NaN on 0 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: NaN
F-statistic: NaN on 2 and 0 DF, p-value: NA
Shrinkage methods
“Classical” solution: subset selection.
An alternative to subset selection is to fit the model using all p predictors, but constrain, or regularize the coefficients (=you ‘shrink’ the coefficients)
Two main types:
Ridge regression: pushes the \beta_j towards zero, but all predictors included
Lasso regression: pushes the \beta_j towards zero, some predictors excluded
(There’s also the elastic net, which is a combination of ridge and lasso)
The shrinkage penalty \lambda\sum_{j=1}^p\beta^2_j restricts the growth of coefficient estimates.
\lambda = 0: parameter estimates not penalised at all, hence this is “just” linear regression (you obtain the least squares best model, including all parameters).
\lambda \to \infty: parameter estimates heavily penalised, coefficients pushed to zero, model is \hat{y}_i = \hat{\beta}_0 = \bar{y}.
Note: the \beta_0 estimate is not penalised (we are trying to “constrain” the effect of predictors on the response).
Also called “L^2 regularisation”, as the penalty is the square of the \beta_j’s L^2 norm.
Only difference: penalty is a function of the absolute value of coefficient estimates.
This can force some \beta_j to exactly zero: creates easier to interpret models.
You could say this performs “variables selection” (like the best subset approach).
Also called “L^1 regularisation”, as the penalty is the \beta_j’s L^1 norm.
Important note
Before fitting ridge & lasso regression, we should standardise\boldsymbol{X}’s columns so their sample variances are 1 (and mean is 0).
Otherwise, we could be penalising some \beta_j “a lot” simply because the jth covariate takes “small values” compared to other variables. That would not make sense.
The \text{R} package glmnet() we use for ridge & lasso regression will do this for us (by default).
Elastic net model
Combines ridge and lasso penalties, so you minimise
0 < \alpha < 1 is elastic net, a compromise between ridge and lasso.
The glmnet package fits elastic net models, so you have to choose \alpha=0 or \alpha=1 to get ridge or lasso.
“Ridge regression” refers to linear regression with a ridge penalty.
“Lasso regression” refers to linear regression with a lasso penalty.
But, you can also put a ridge or lasso penalty on logistic regression, Poisson regression, or any GLM. In that case, the penalty is added to the deviance (rather than the RSS). Note this is conveniently implemented in the glmnet package.
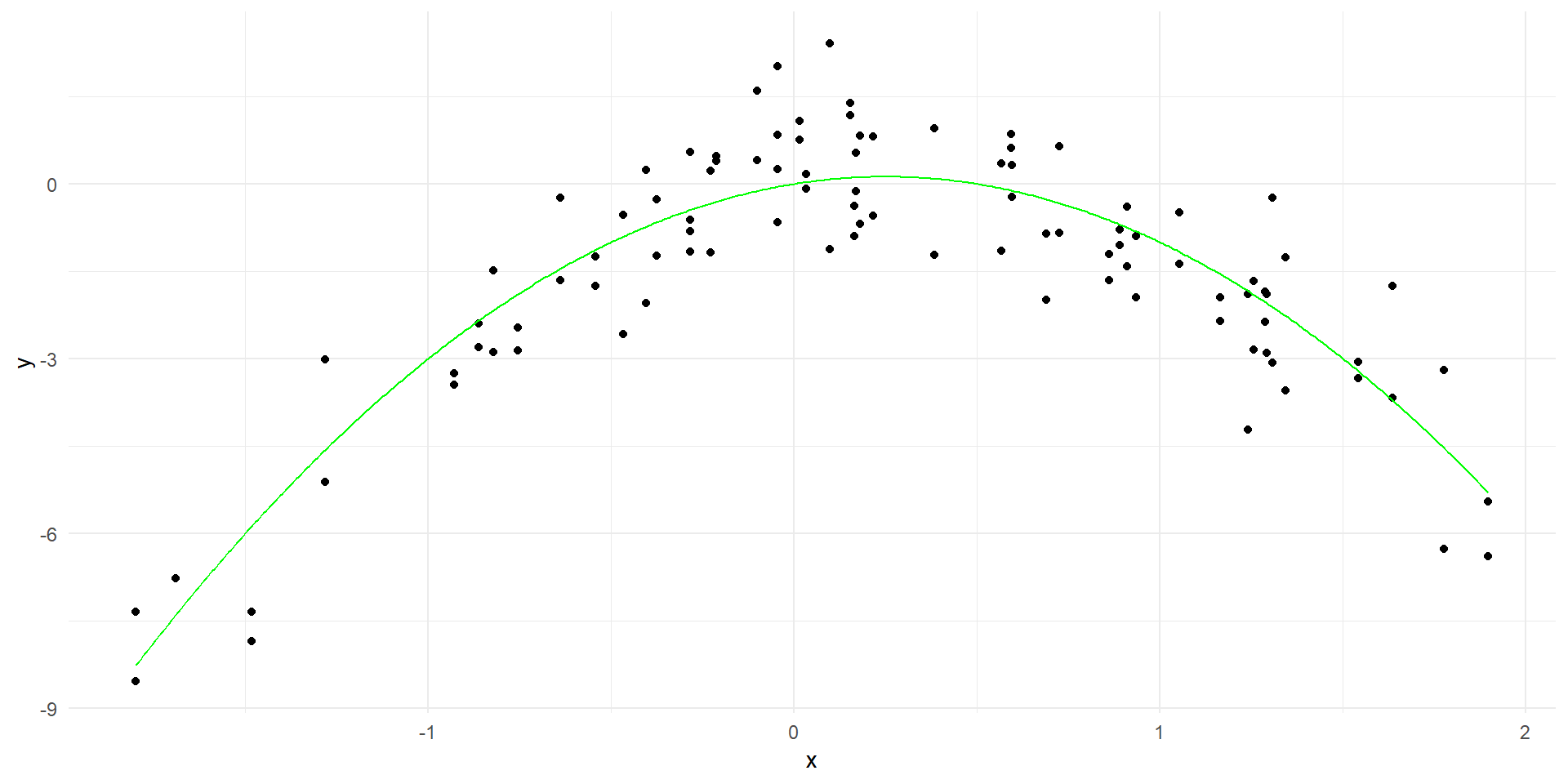
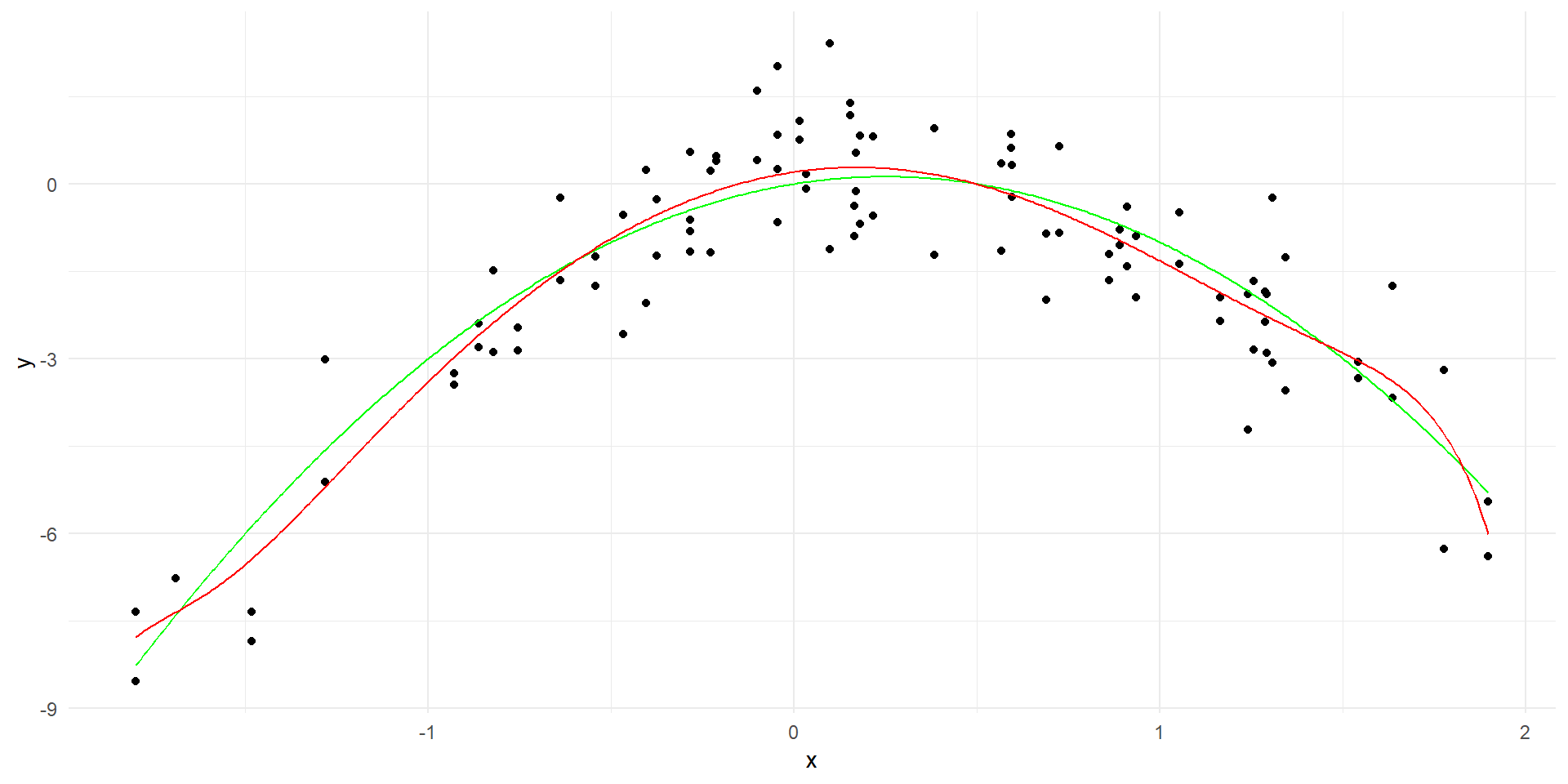
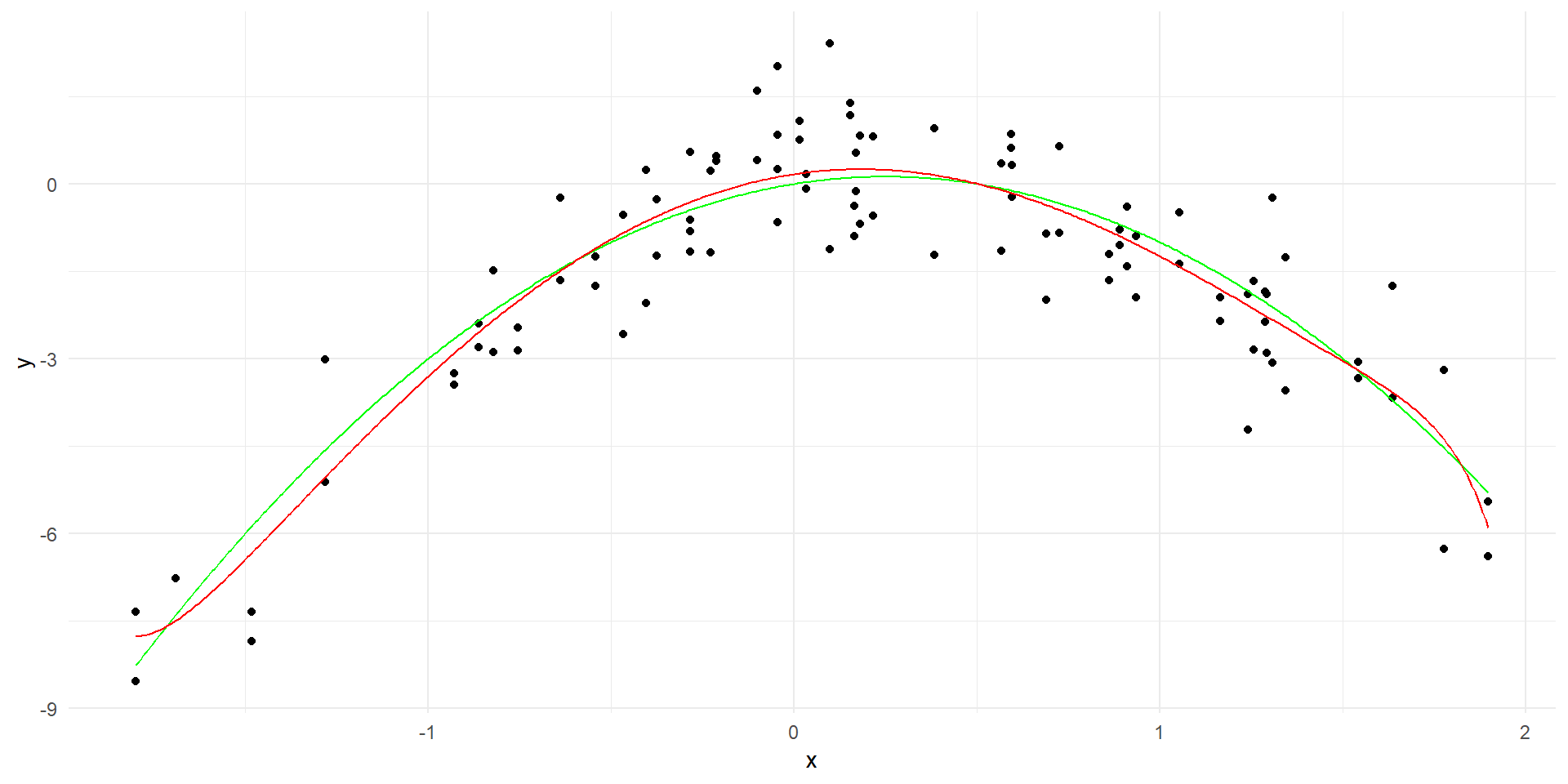
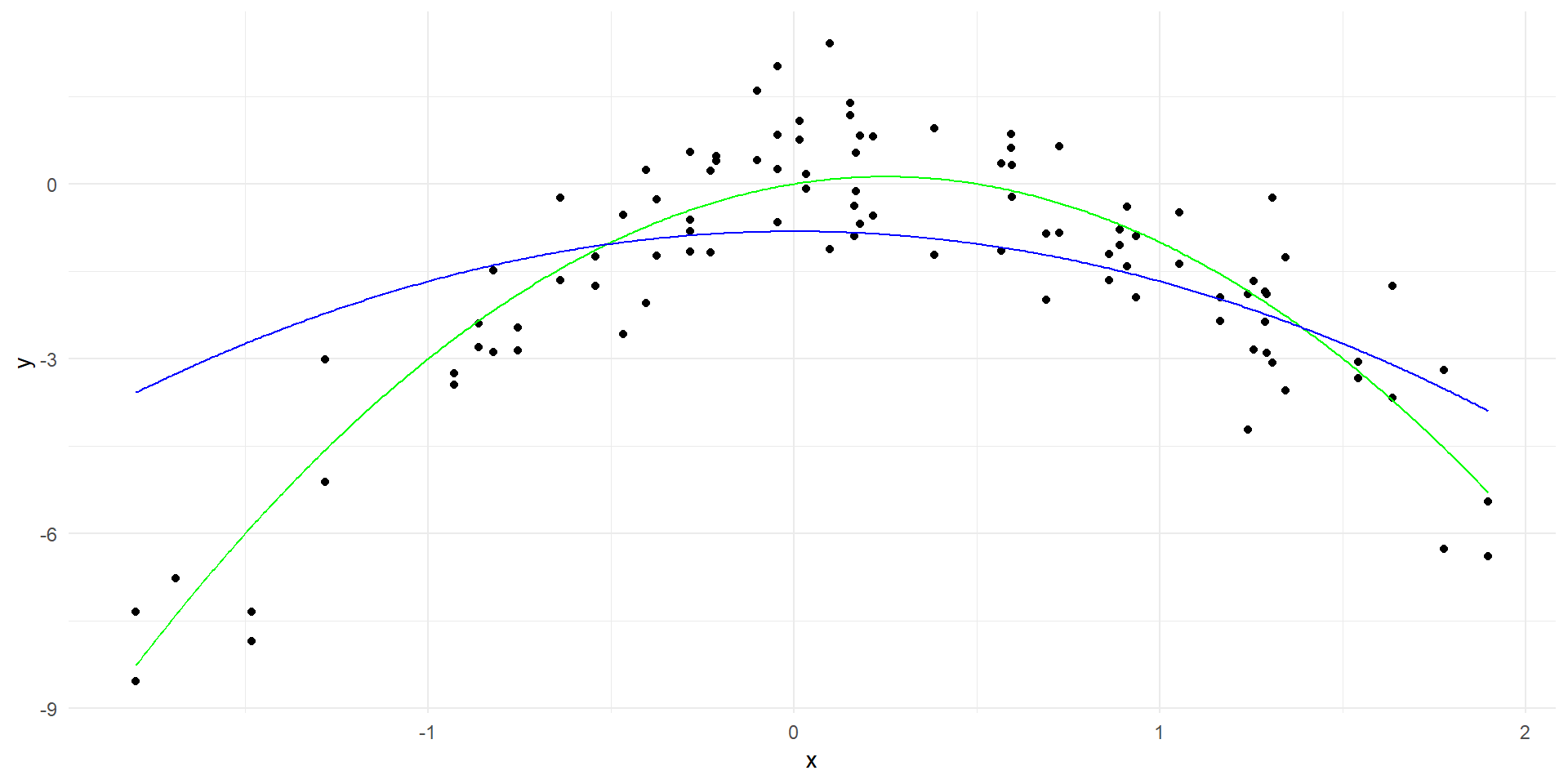
set.seed(4)x <-rnorm(50)y <- x -2*x^2+rnorm(100)data <-data.frame(x = x, y = y)# Generate true curvex_grid <-seq(min(x), max(x), length=500)y_true <- x_grid -2*x_grid^2true_curve <-data.frame(x = x_grid, y = y_true)# Plot the data with the true curveggplot(data, aes(x = x, y = y)) +geom_point() +geom_line(data = true_curve, aes(x = x, y = y), color ="green") +labs(x ="x", y ="y") +theme_minimal()
Polynomial regression
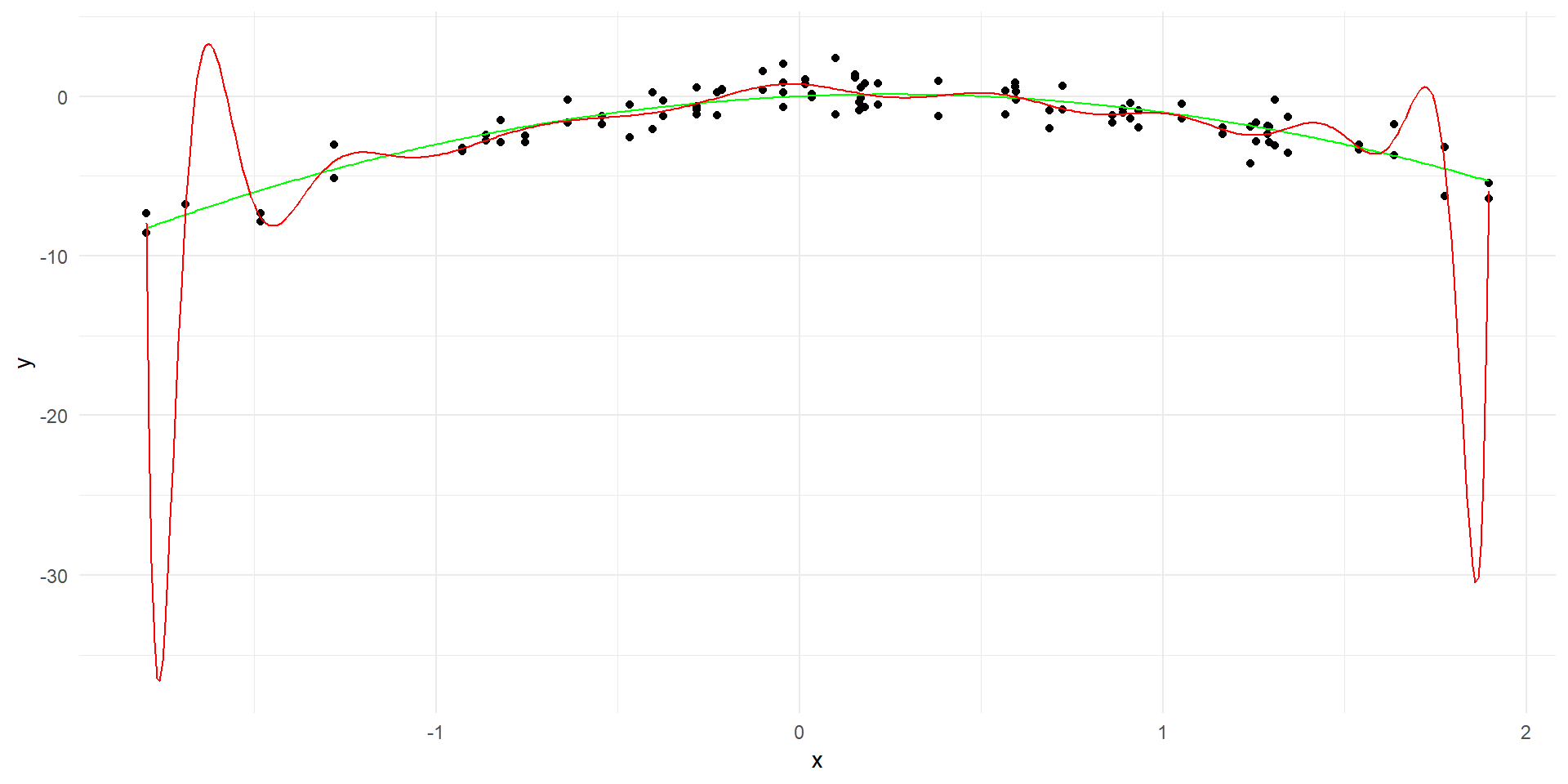
Code
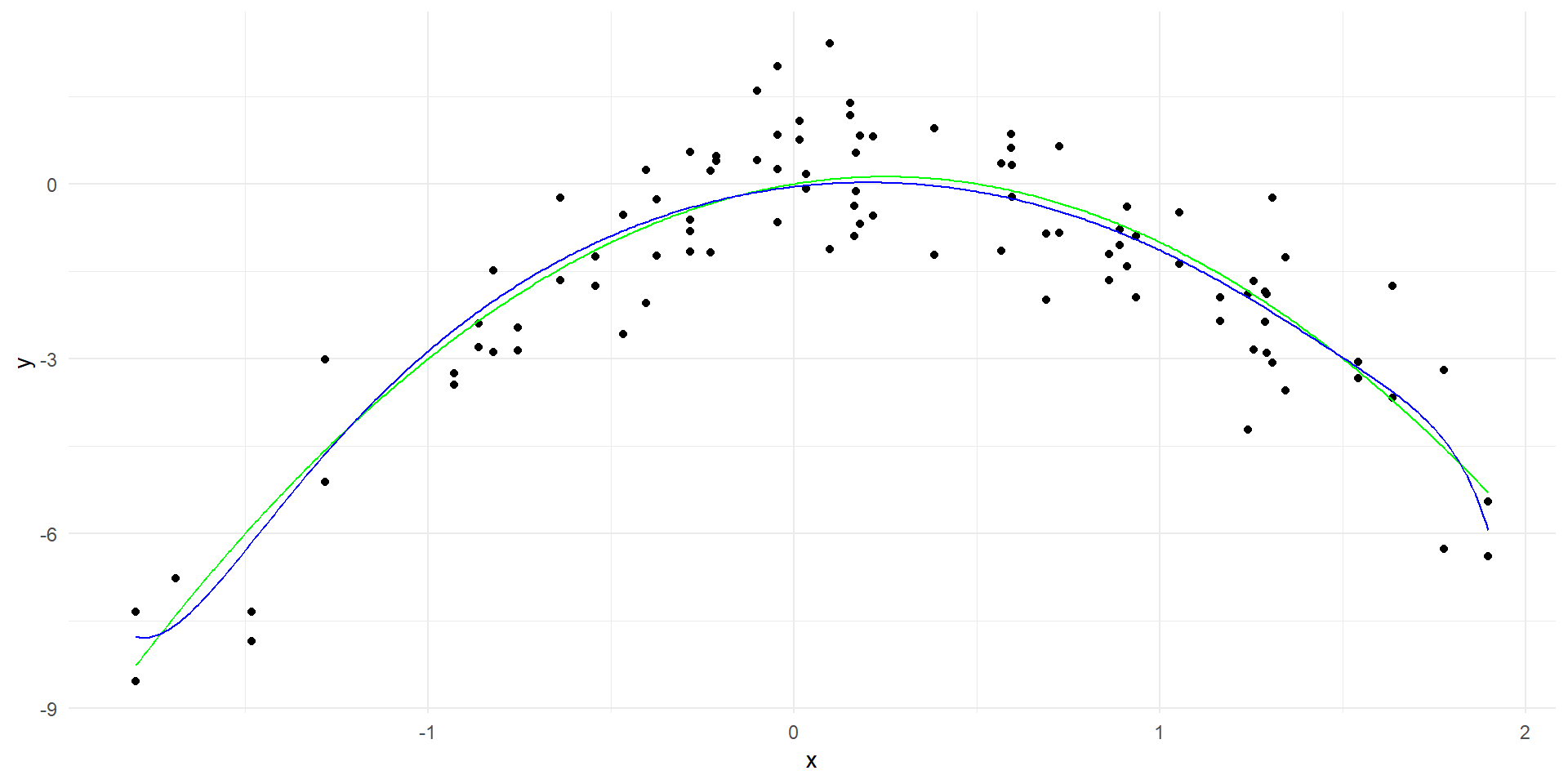
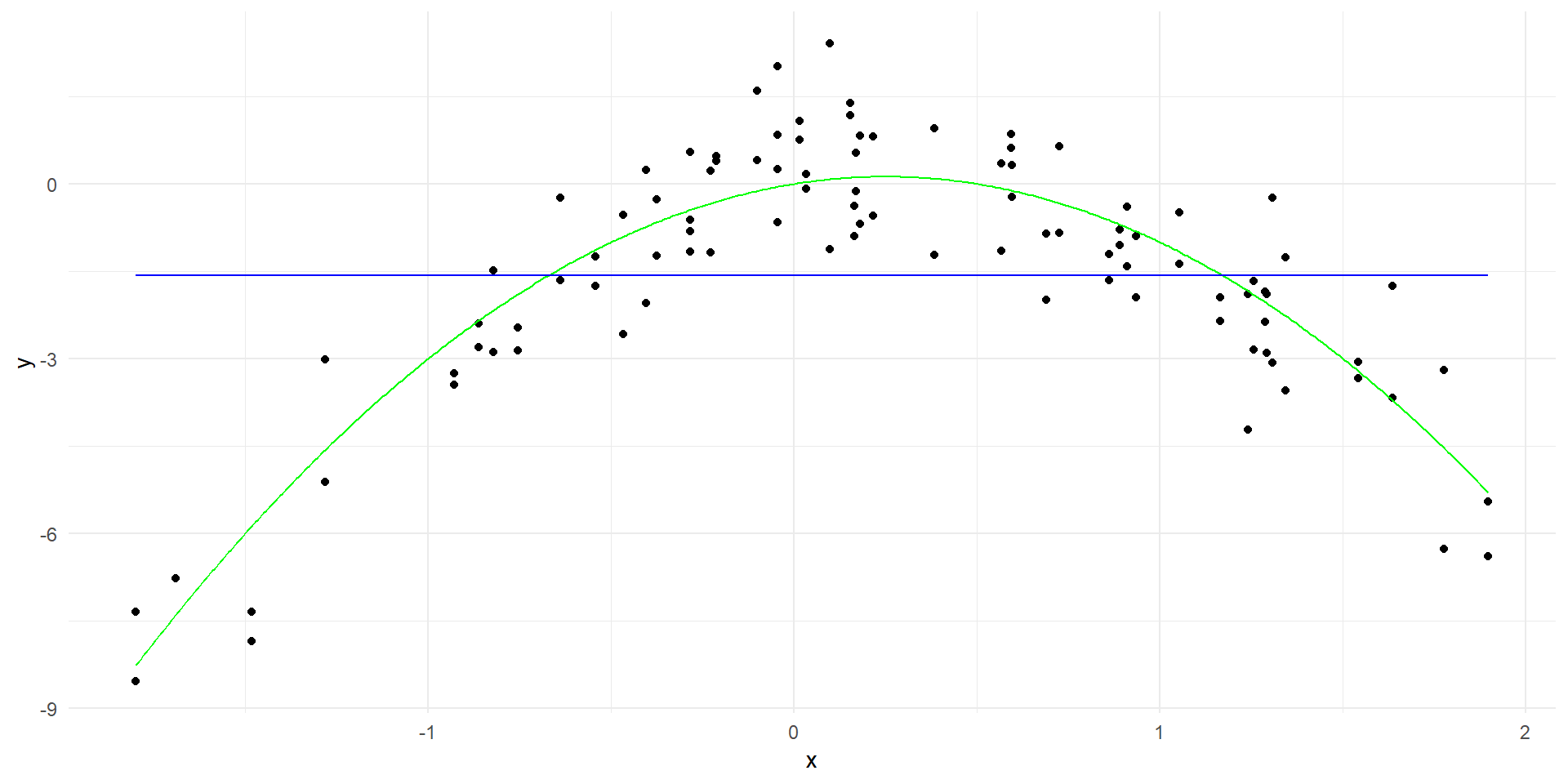
# Fit a linear modellinear_model <-lm(y ~poly(x, 20, raw=TRUE), data = data)# Generate predictions over the datay_hat <-predict(linear_model, data.frame(x = x_grid))linear_predictions <-data.frame(x = x_grid, y = y_hat)ggplot(data, aes(x = x, y = y)) +geom_point() +geom_line(data = true_curve, aes(x = x, y = y), color ="green") +geom_line(data = linear_predictions, aes(x = x, y = y), color ="red") +labs(x ="x", y ="y") +theme_minimal()
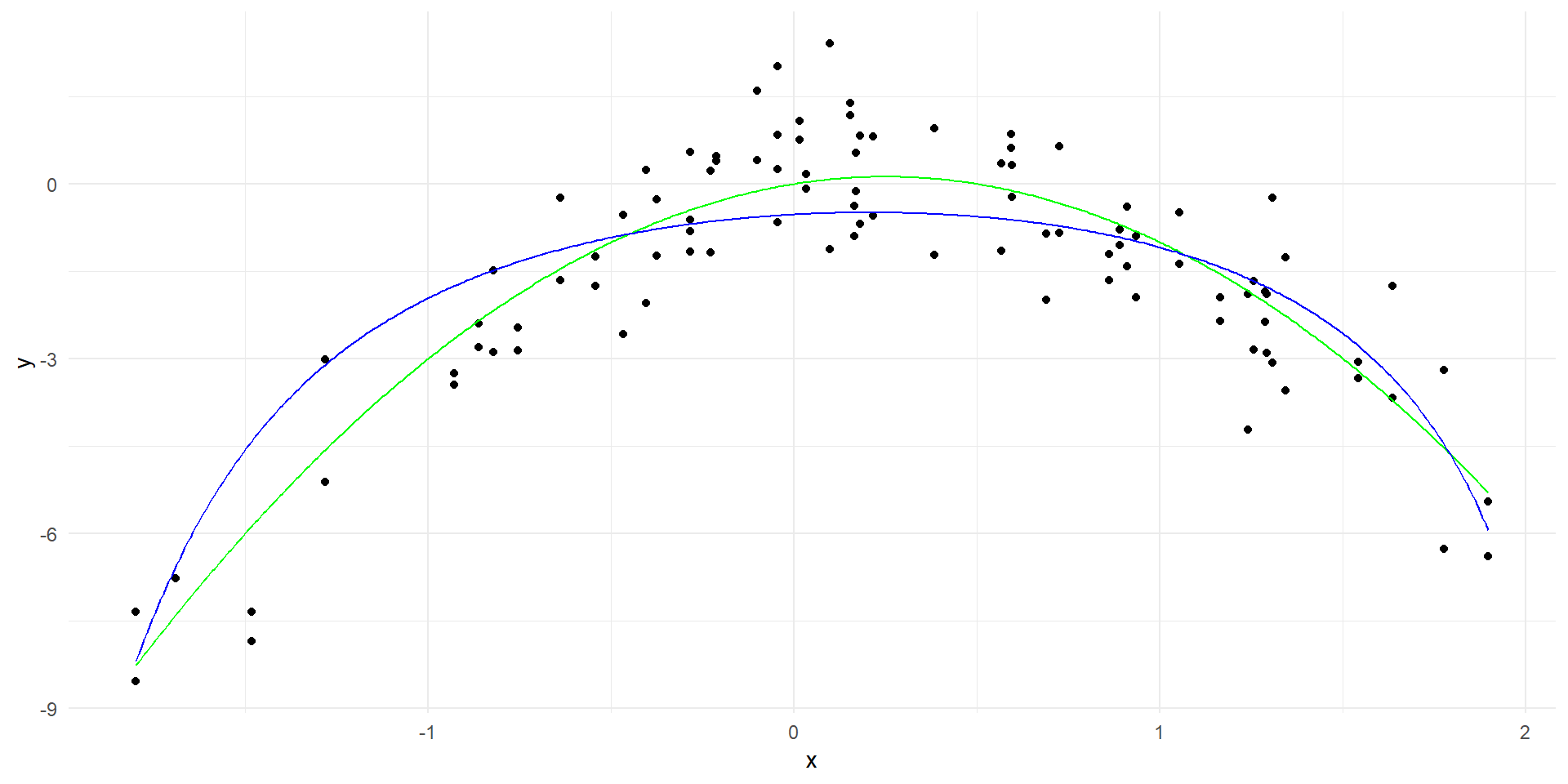
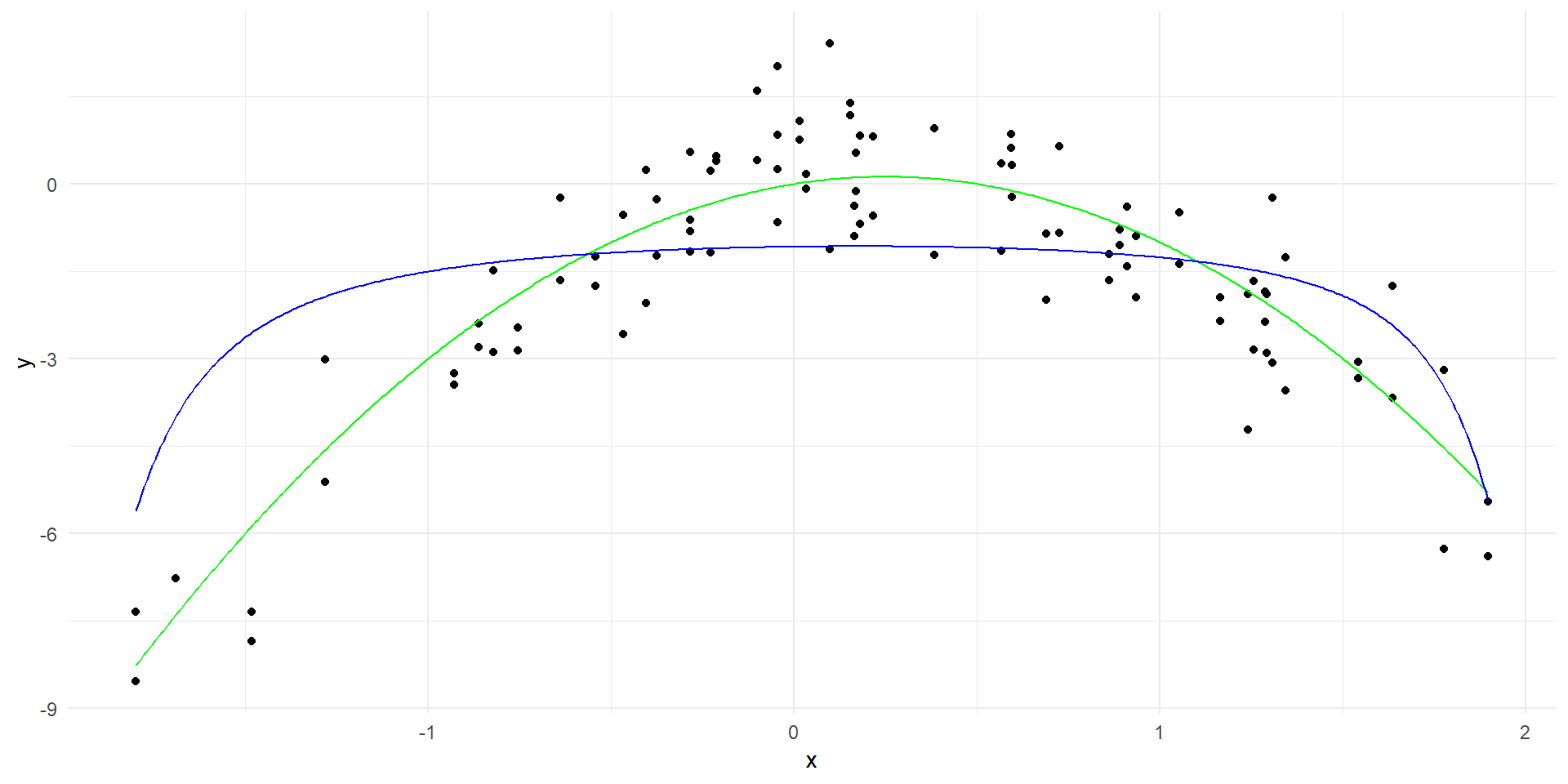
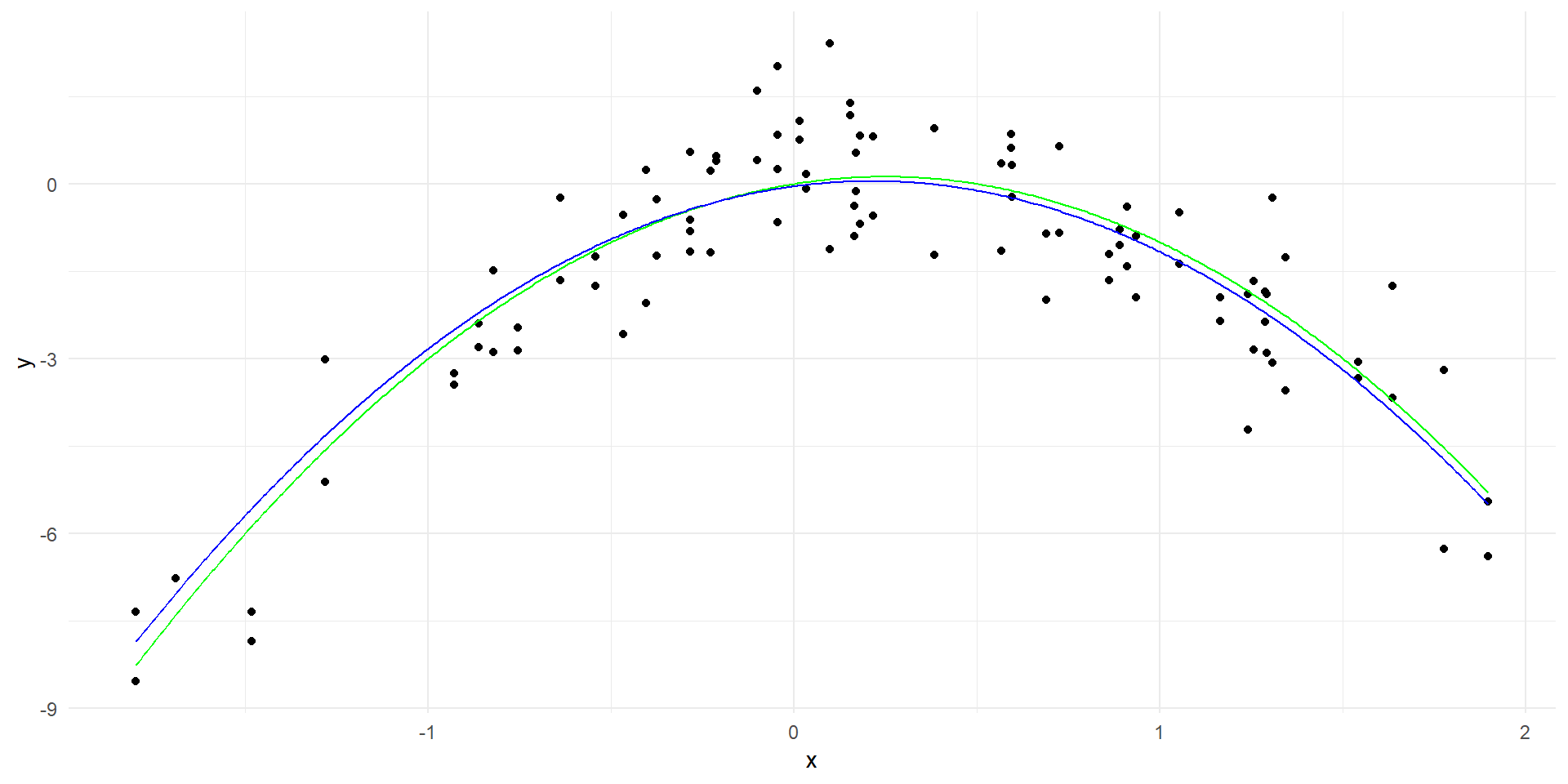
# Create a data frame with the predictorsx_poly <-model.matrix(~poly(x, 20, raw=TRUE), data = data)[, -1]x_grid_poly <-model.matrix(~poly(x_grid, 20, raw=TRUE))[, -1]colnames(x_grid_poly) <-colnames(x_poly)ridge_model <-glmnet(x_poly, y, alpha =0, lambda=c(0.01, 0.1, 1, 10))# Generate predictions over the datay_hat <-predict(ridge_model, newx=x_grid_poly, s =0.01)linear_predictions <-data.frame(x = x_grid, y = y_hat)names(linear_predictions) <-c("x", "y")ggplot(data, aes(x = x, y = y)) +geom_point() +geom_line(data = true_curve, aes(x = x, y = y), color ="green") +geom_line(data = linear_predictions, aes(x = x, y = y), color ="red") +labs(x ="x", y ="y") +theme_minimal()
load_gene_data <-function() {# Read in the information about the study participants labels <-read.csv("2912Table2.csv", header =TRUE) er <- labels[,14] n <-nrow(labels) n1 <-sum(er) # Should be 65 n2 <- n - n1 # Should be 99-65=34# Read in the gene expressions, remove meta-info and NA rows genes <-read.csv("2912Table3.csv", header =TRUE) genes <- genes[ , -(1:6)] genes <-t(as.matrix(genes[rowSums(is.na(genes)) ==0, ])) df <-as.data.frame(genes) df$er <- er df}
“Sotiriou et al. (2003) described a breast cancer study with 99 women divided into two groups according to their oestrogen receptor status. The ER+ group (65 women) are those women where the cancer has receptors for oestrogen, and the ER− group (34 women) are those without receptors. Out of 7650 variables there are 4404 measured in all 99 samples, and we use these variables for our analysis.”
# Split and convert to matrices for `glmnet`set.seed(123) # For reproducibilitytest_index <-sample(1:nrow(df), 0.2*nrow(df))test <- df[test_index, ]train_val <- df[-test_index, ]# Prepare data for glmnetX <-model.matrix(er ~ ., data = train_val)[, -1]y <- train_val$erX_test <-model.matrix(er ~ ., data = test)[, -1]y_test <- test$er
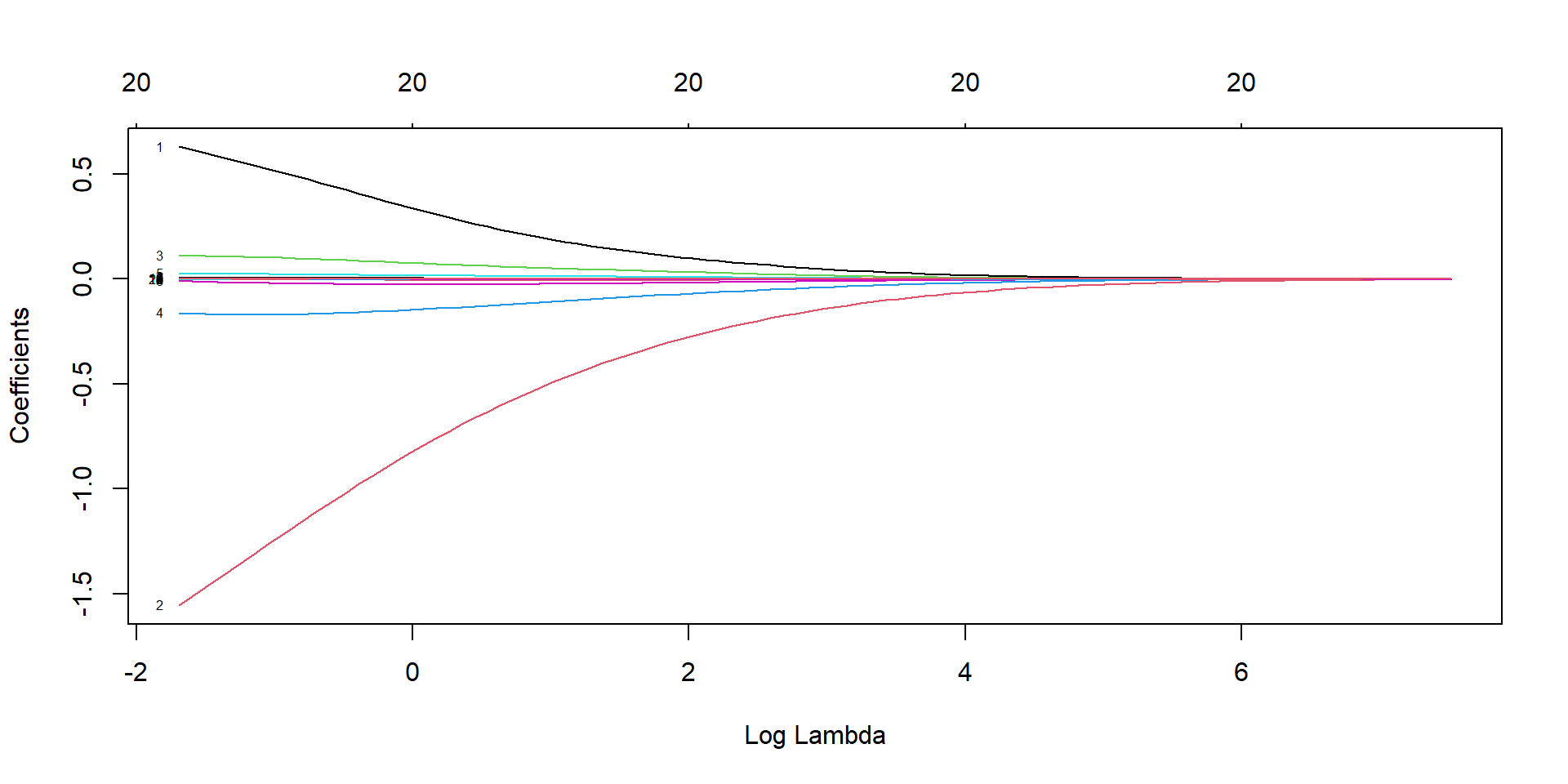
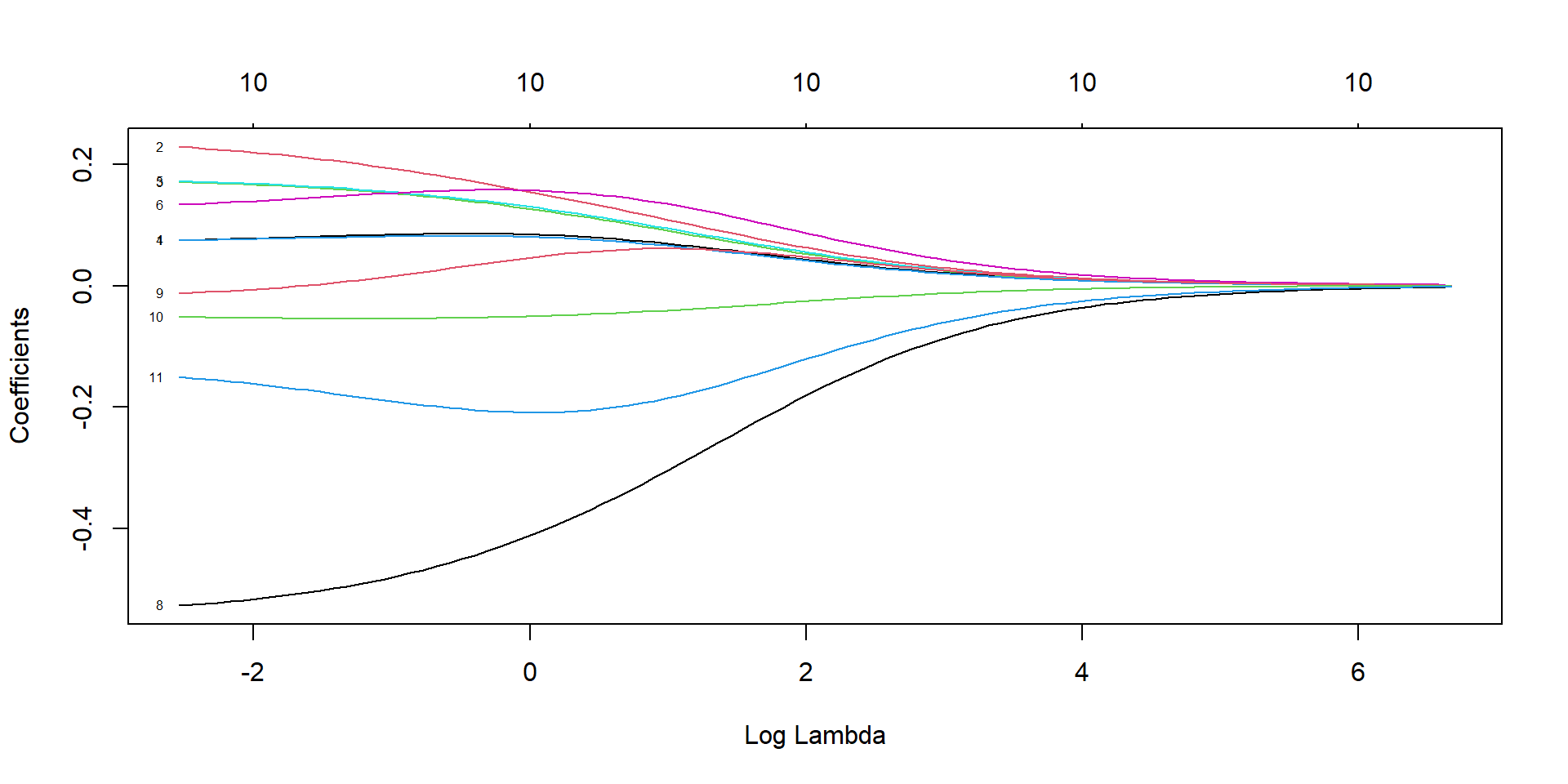
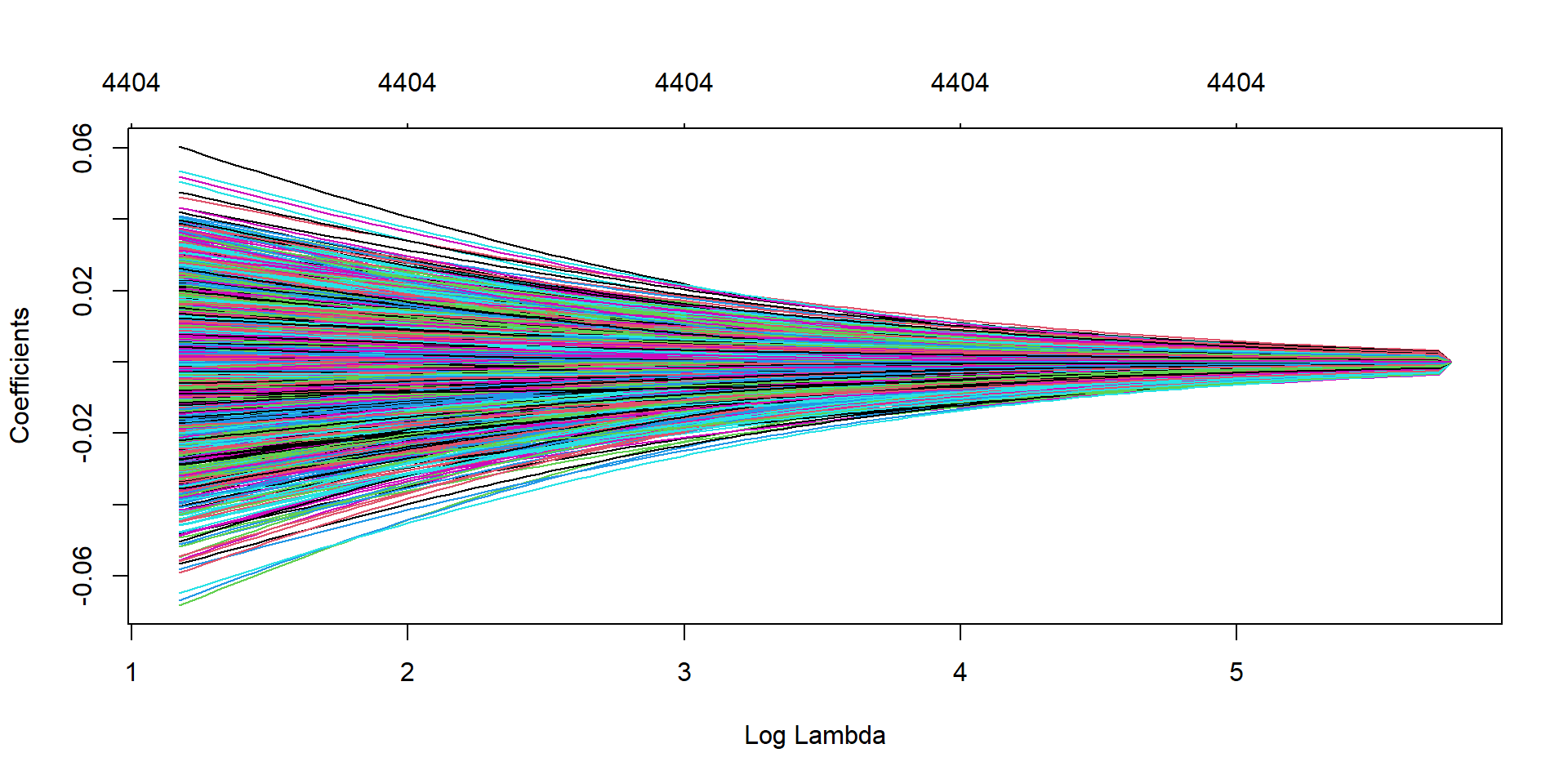
Ridge regression
ridge_model <-glmnet(X, y, family ="binomial", alpha =0)plot(ridge_model, xvar="lambda")
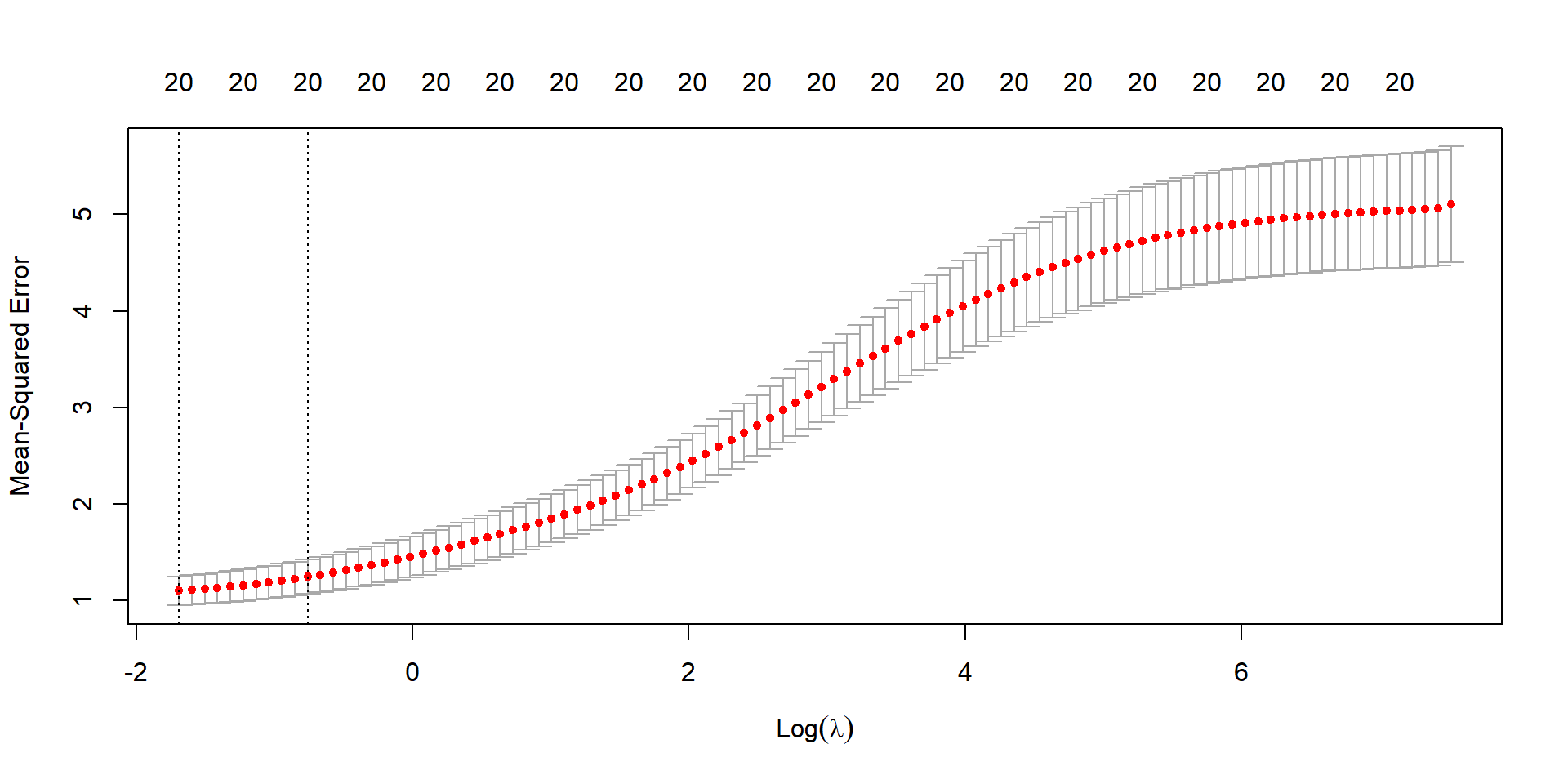
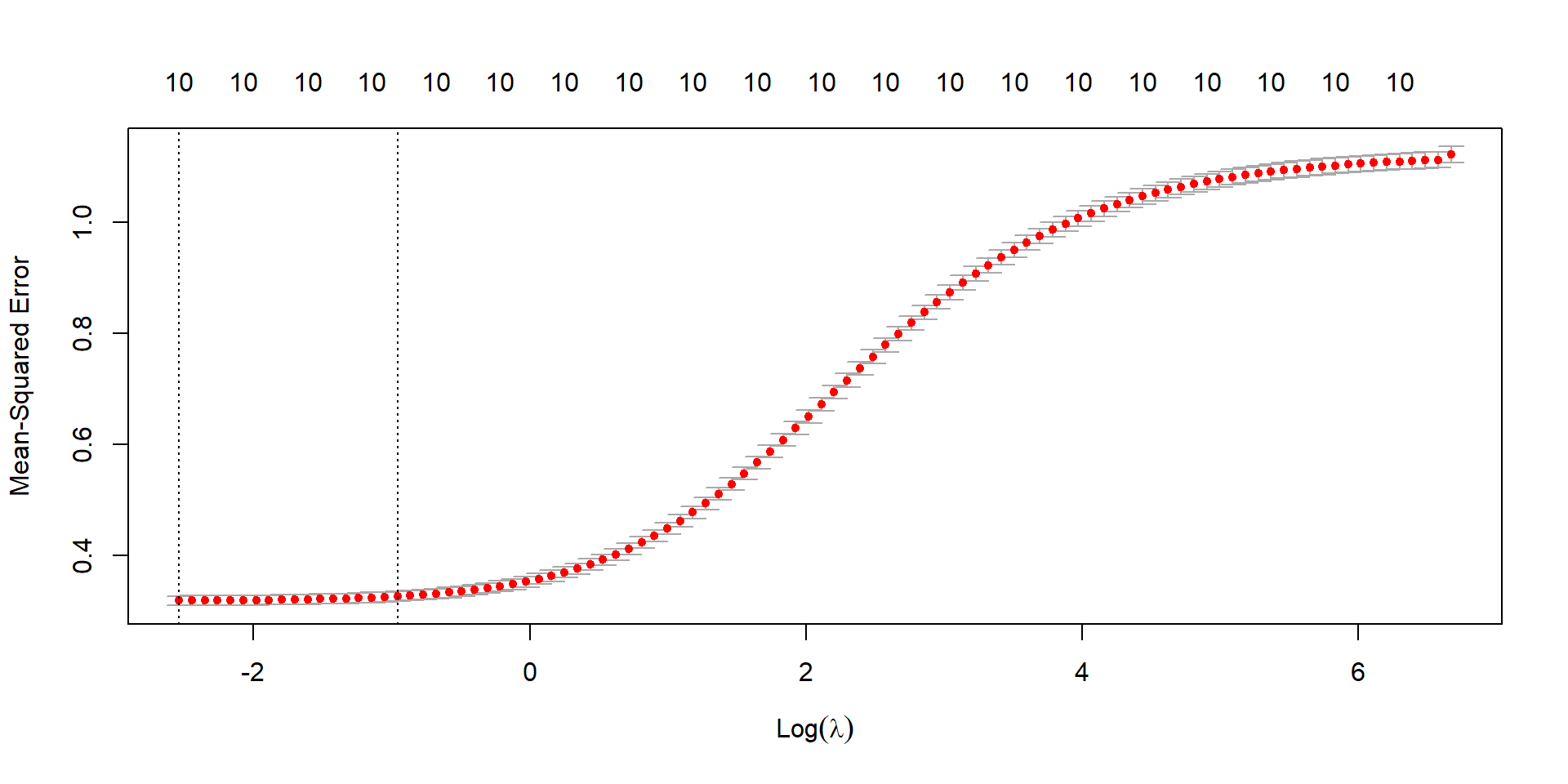
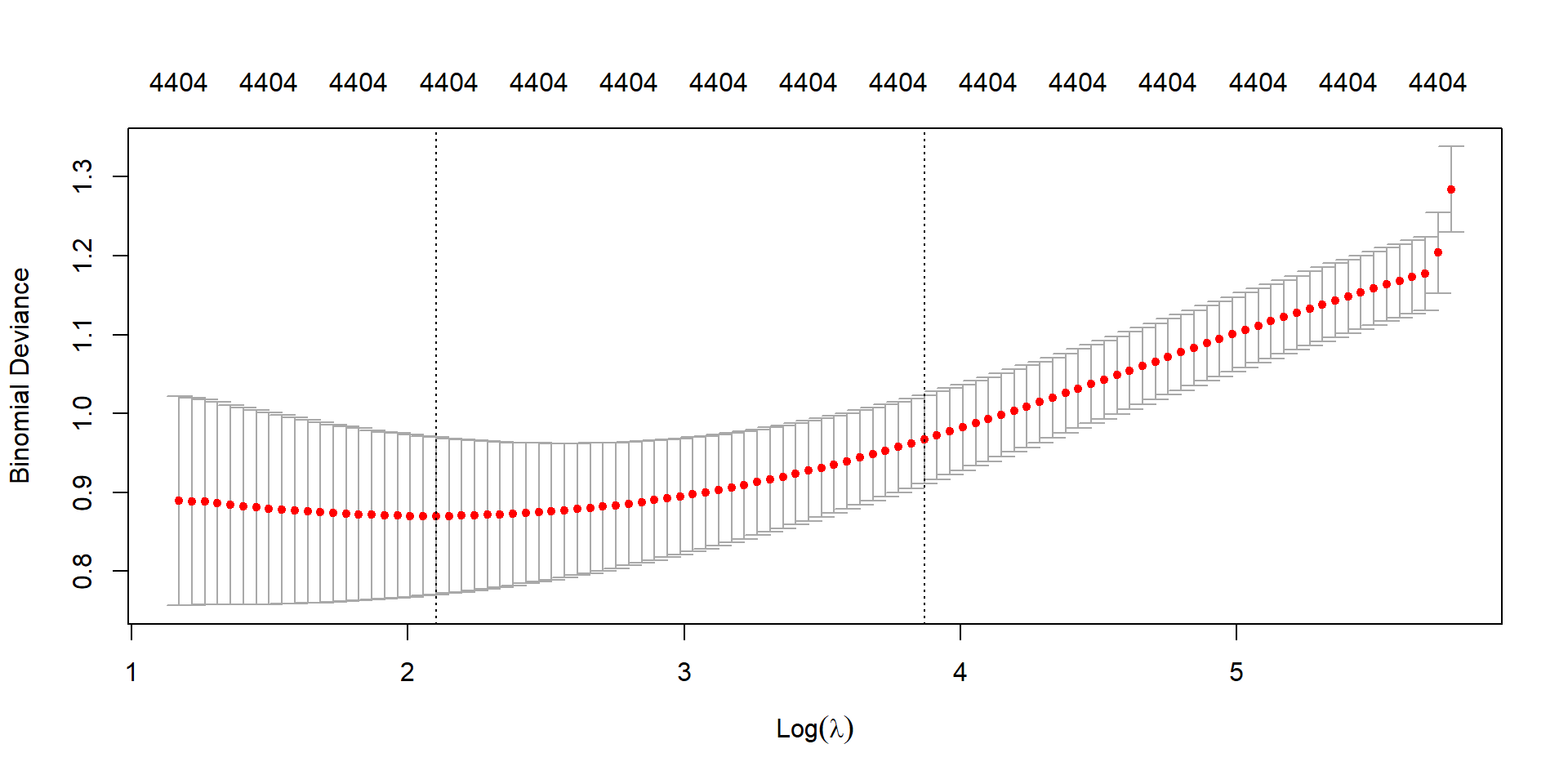
Ridge CV (Deviance)
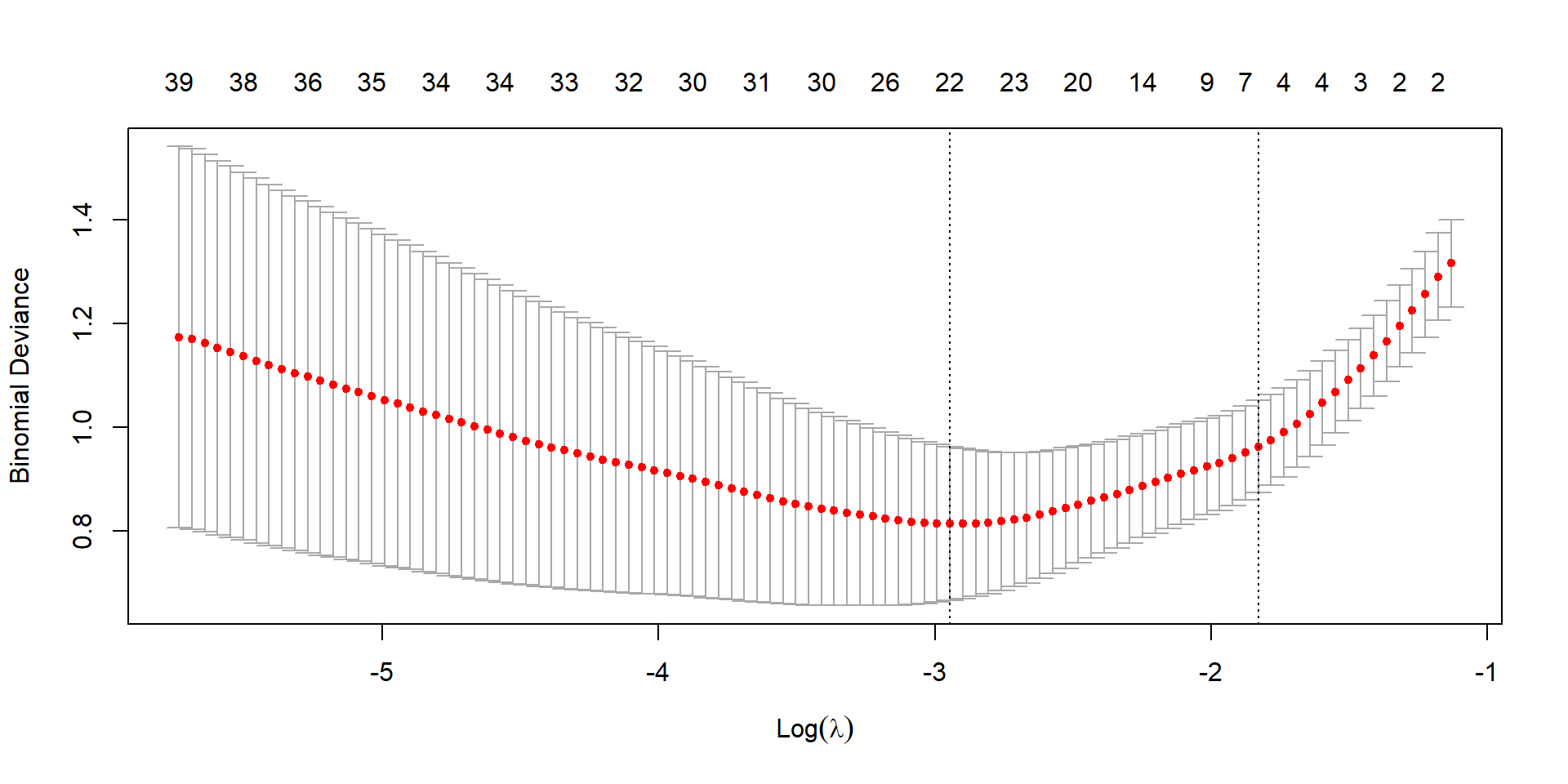
cv_ridge <-cv.glmnet(X, y, family ="binomial", alpha =0)plot(cv_ridge)
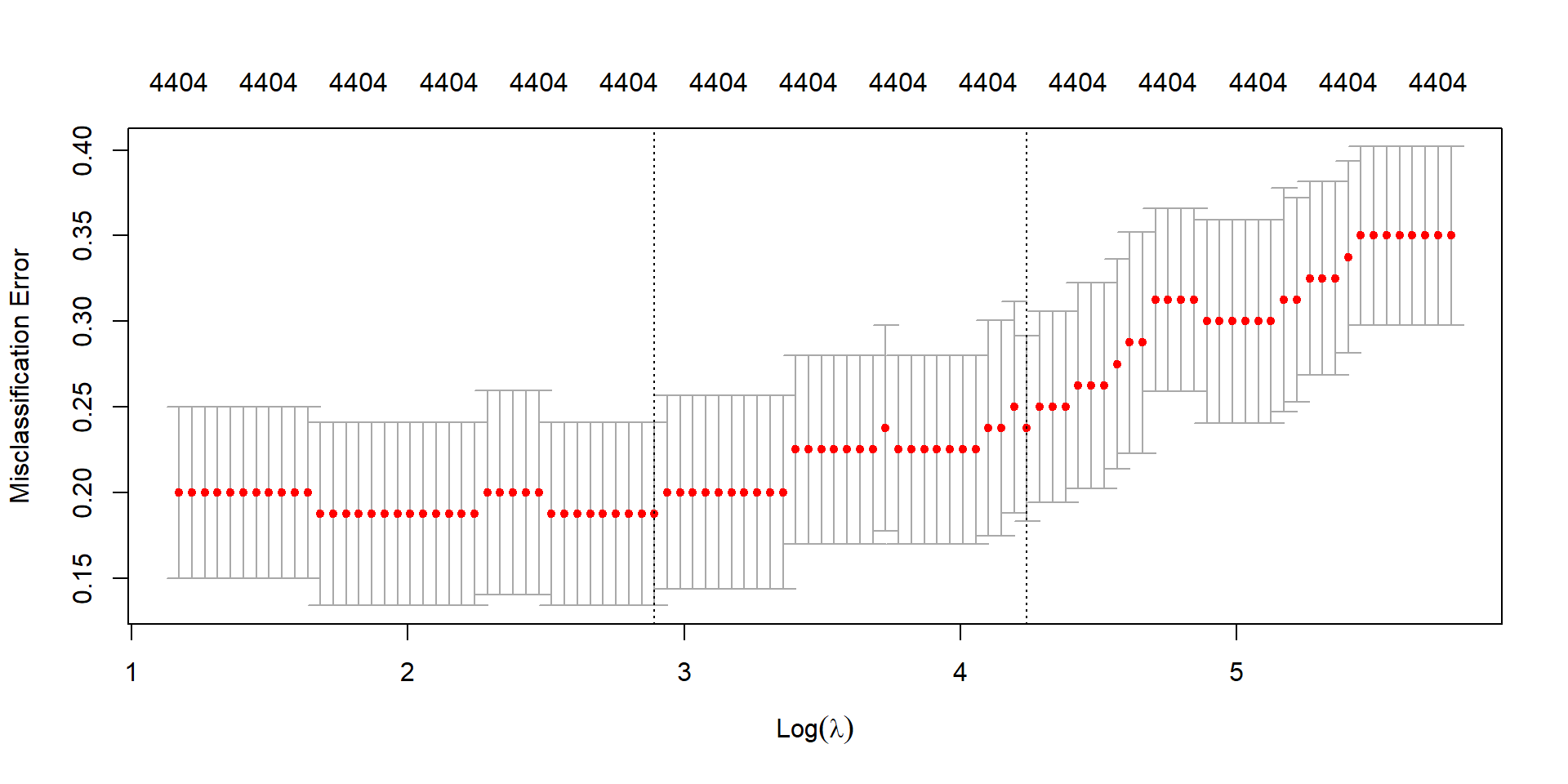
Ridge CV (Classification Error Rate)
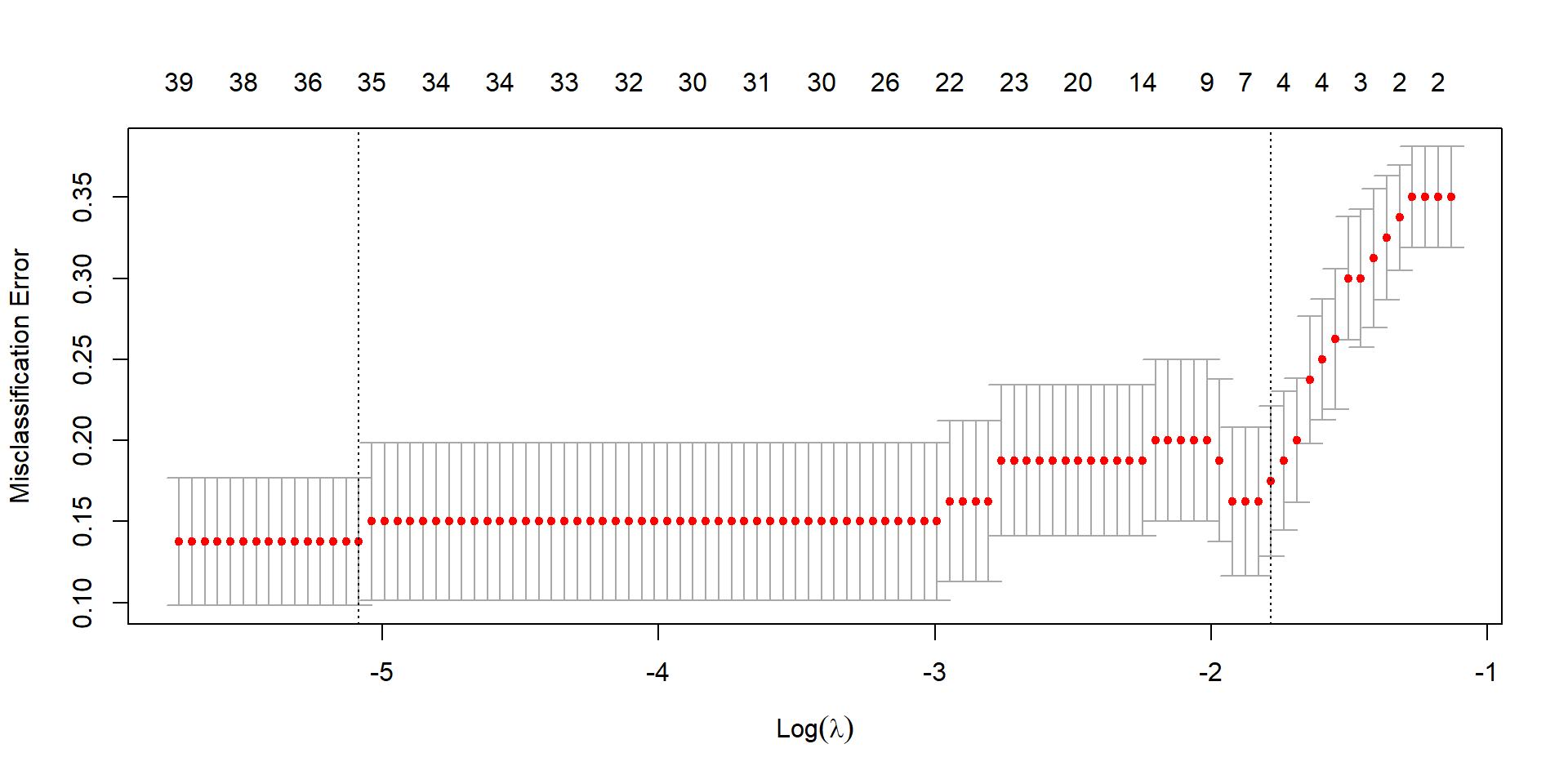
cv_ridge <-cv.glmnet(X, y, family ="binomial", alpha =0, type.measure ="class")plot(cv_ridge)
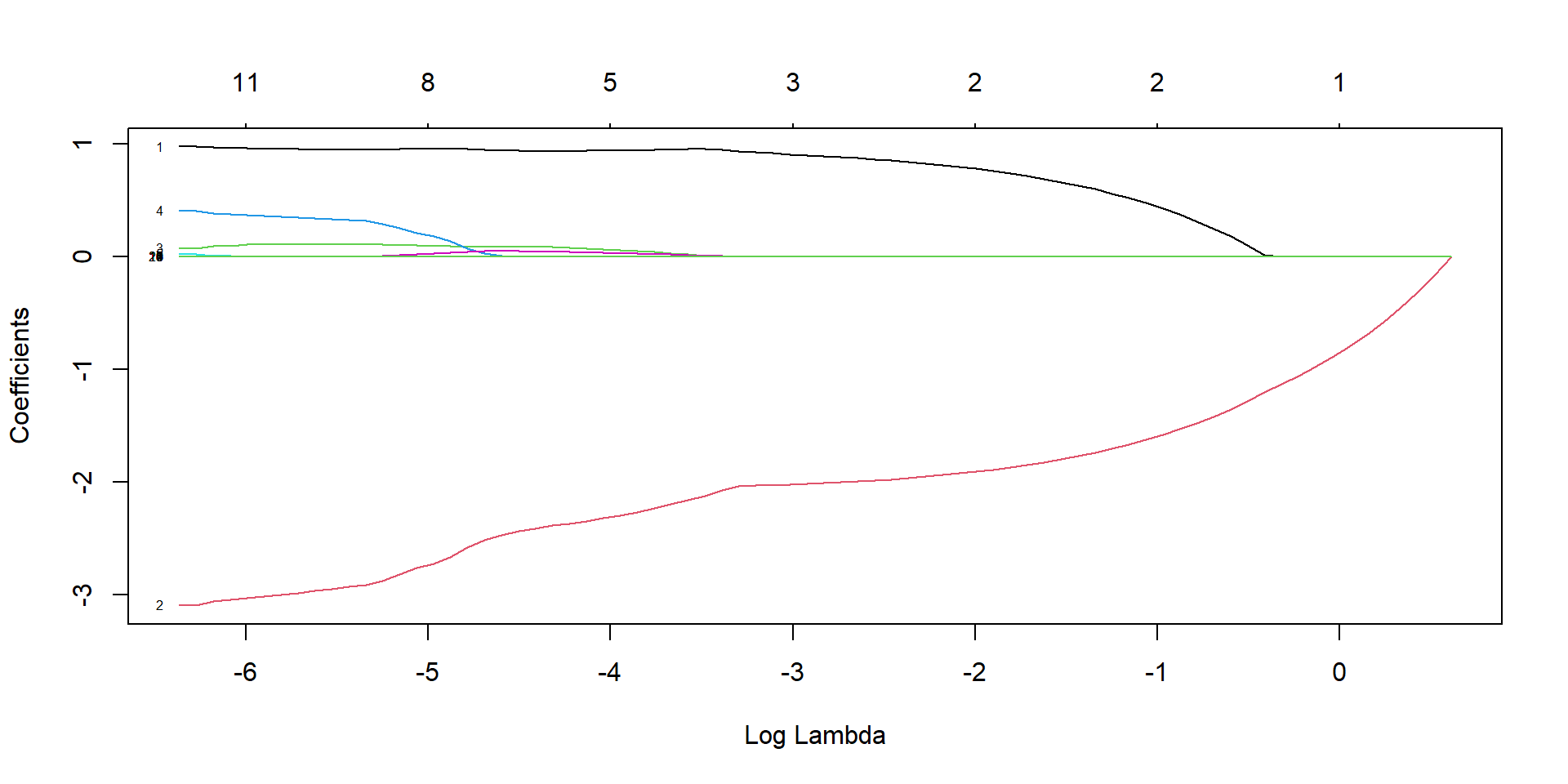
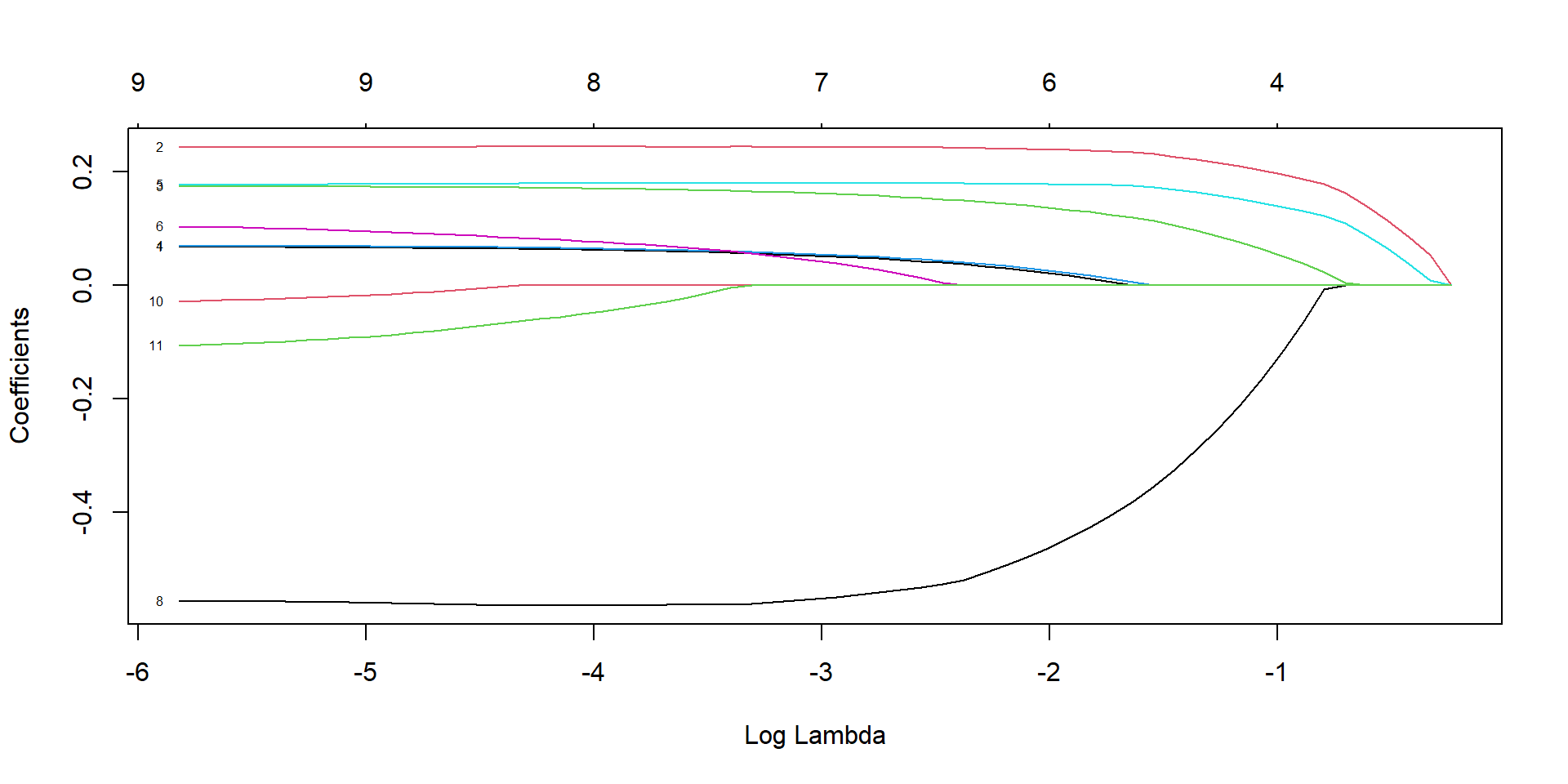
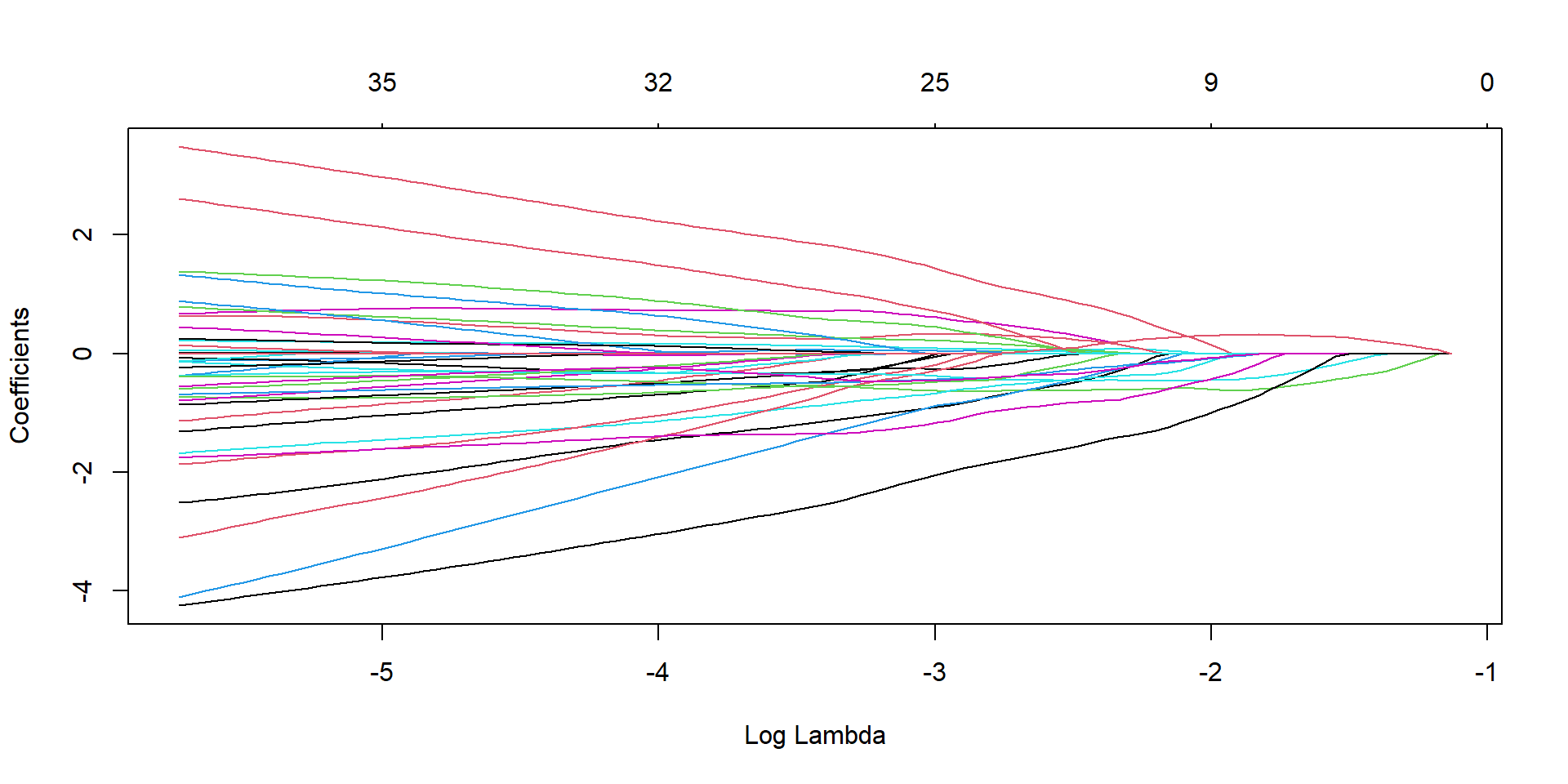
Lasso regression
lasso_model <-glmnet(X, y, family ="binomial", alpha =1)plot(lasso_model, xvar="lambda")
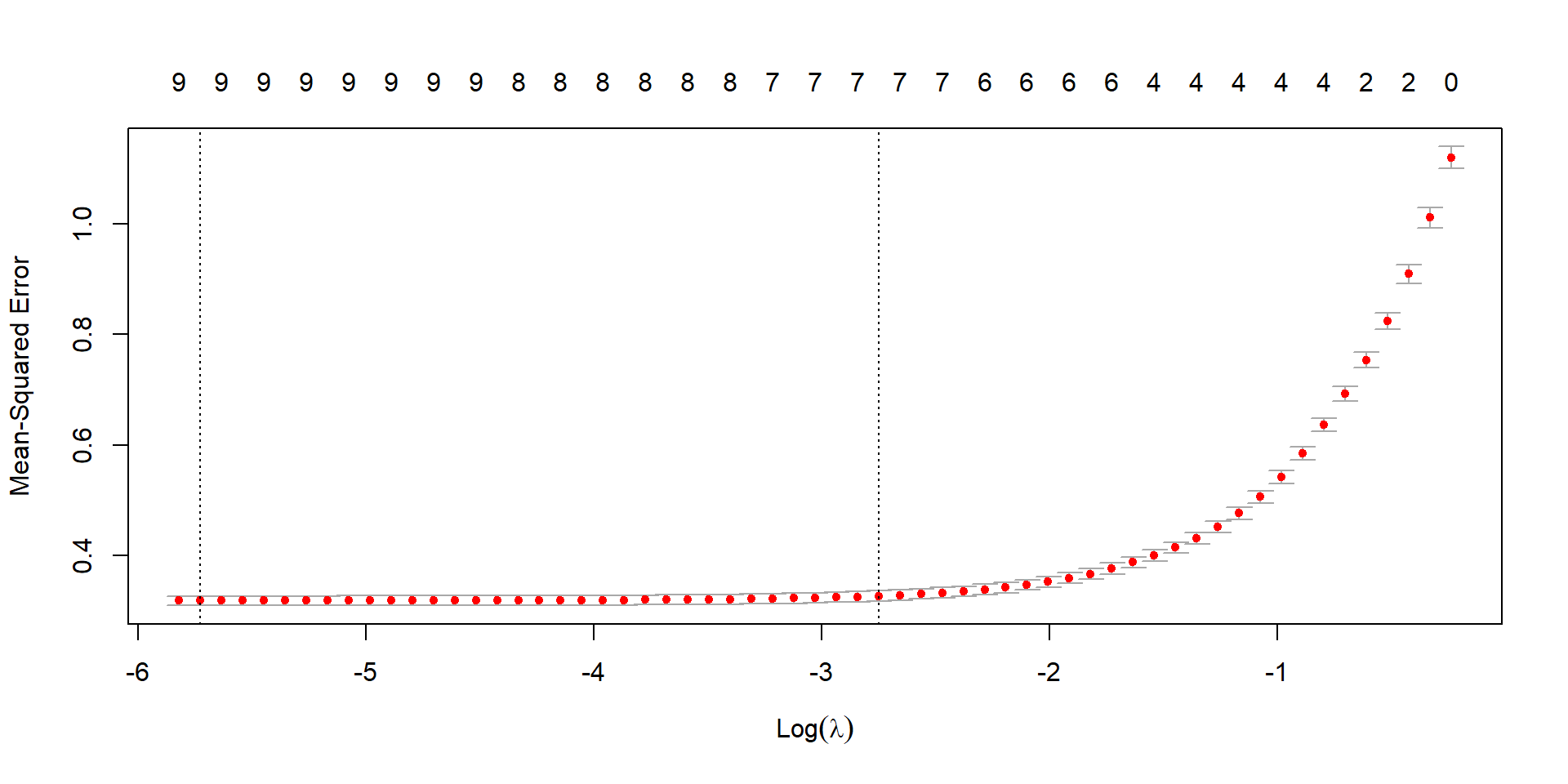
Lasso CV (Deviance)
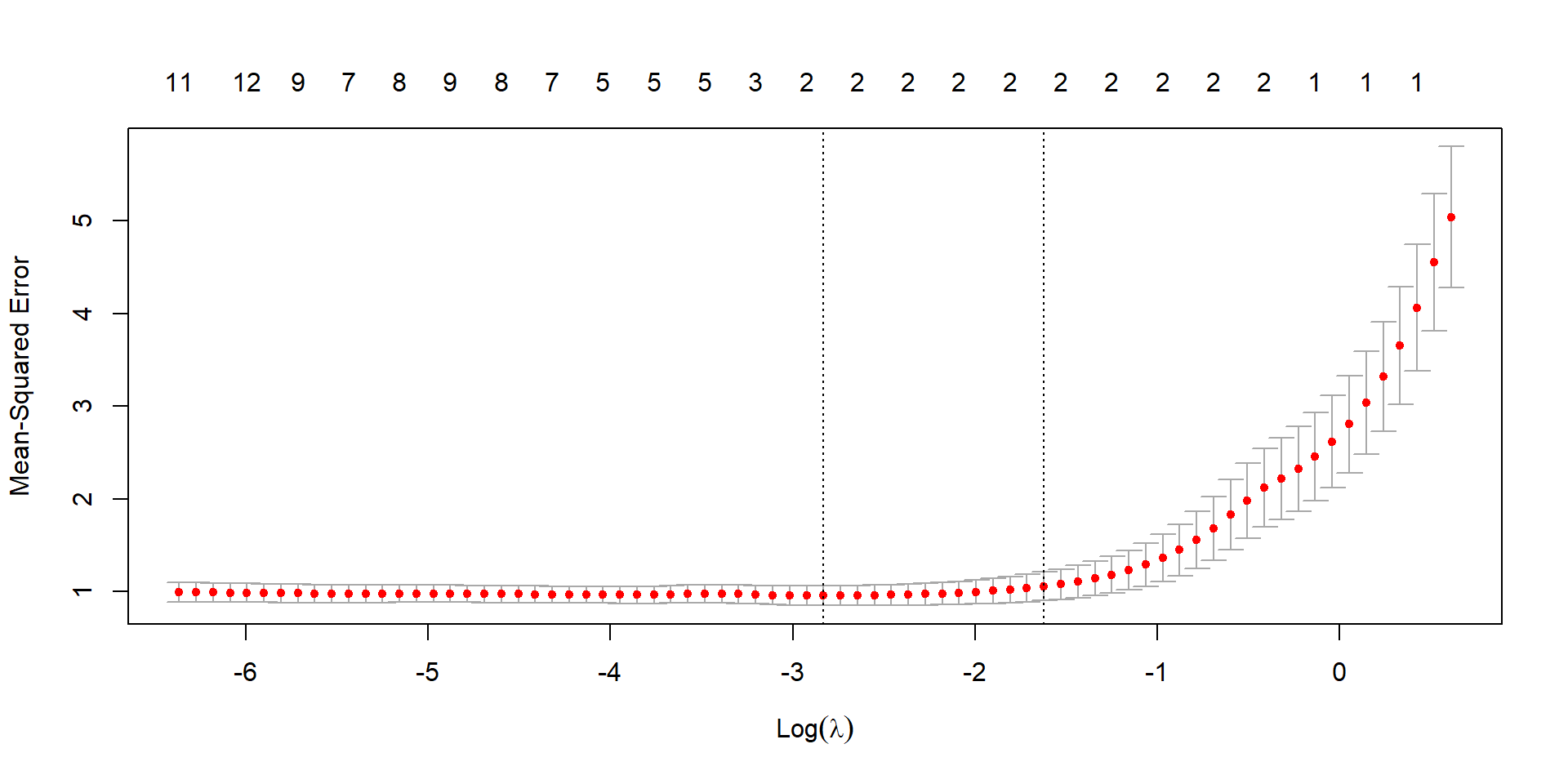
cv_lasso <-cv.glmnet(X, y, family ="binomial", alpha =1)plot(cv_lasso)
Lasso CV (Classification Error Rate)
cv_lasso <-cv.glmnet(X, y, family ="binomial", alpha =1, type.measure ="class")plot(cv_lasso)
Select a winner & test it
(ridge_cv_error <-min(cv_ridge$cvm))
[1] 0.1875
(lasso_cv_error <-min(cv_lasso$cvm))
[1] 0.1375
sum(coef(cv_lasso, s ="lambda.min") !=0)
[1] 38
sum(coef(cv_lasso, s ="lambda.1se") !=0)
[1] 6
if (ridge_cv_error < lasso_cv_error) { best_model <- cv_ridge model_type <-"ridge"} else { best_model <- cv_lasso model_type <-"lasso"}print(paste("Selected model type:", model_type))
[1] "Selected model type: lasso"
y_pred <-predict(best_model, X_test, type ="response", s ="lambda.min") >0.5test_accuracy <-mean(y_test == y_pred)print(paste("Test set error rate of the selected model:", round(1-test_accuracy,4)))
[1] "Test set error rate of the selected model: 0.1579"
Ridge and Lasso Intuition
Lecture Outline
Linear Regression Recap
Generalised Linear Models Recap
Glassdoor Dataset
Statistical Model Evaluation
Validation Set Approach
k-Fold Cross-Validation
Leave-One-Out Cross-Validation
Regularisation
Regularisation Plots
Regularisation Demos
Ridge and Lasso Intuition
Alternate formulation
Ridge regression: minimise MSE subject to \sum_{j=1}^n \beta_j^2 \leq s Lasso regression: minimise MSE subject to \sum_{j=1}^n |\beta_j| \leq s
Under both ridge and lasso, we have a “budget” to “spend” on the coefficient estimates… we’d better spend it wisely!
Contours of training MSE against the constraint regions for ridge & lasso.
Lasso leads to a pointier solution space: more likely to set parameters to zero.
Ridge / Lasso Regression - Comments
For both ridge and lasso, as \lambda increases (larger penalty), the coefficient estimates of the \beta_j become more biased, but their variances decrease.
One might view the “right” \lambda as one for which only a little bit of bias is introduced, but with a substantial decrease in variance (this would, in practice, lead to better predictions).
For ridge, all parameters remain in the model (with some coefficients potentially very low). This is more difficult to interpret than lasso (though, if our only goal is prediction, that’s not an issue).
Computationally, both are far more efficient than “best-subset”: only one model for each \lambda needs to be computed.
When to use what?
So when should you use elastic net regression, or ridge, lasso, or plain linear regression (i.e., without any regularization)? It is almost always preferable to have at least a little bit of regularization, so generally you should avoid plain linear regression. Ridge is a good default, but if you suspect that only a few features are useful, you should prefer lasso or elastic net because they tend to reduce the useless features’ weights down to zero, as discussed earlier. In general, elastic net is preferred over lasso because lasso may behave erratically when the number of features is greater than the number of training instances or when several features are strongly correlated.
References
Géron, A. (2022). Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow (3rd ed.). O’Reilly Media.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An Introduction to Statistical Learning: with Applications in R. Springer.




{kind=link}