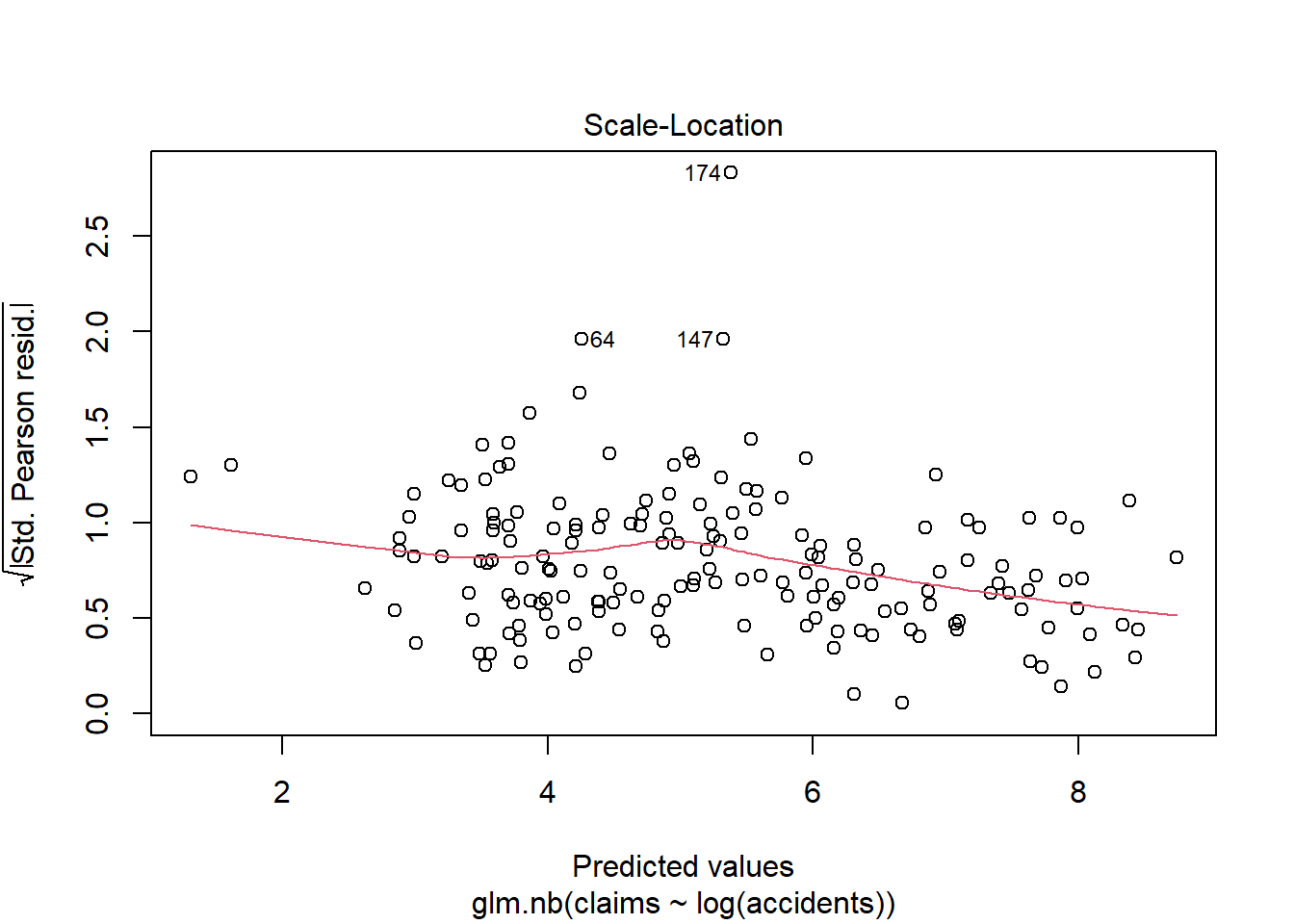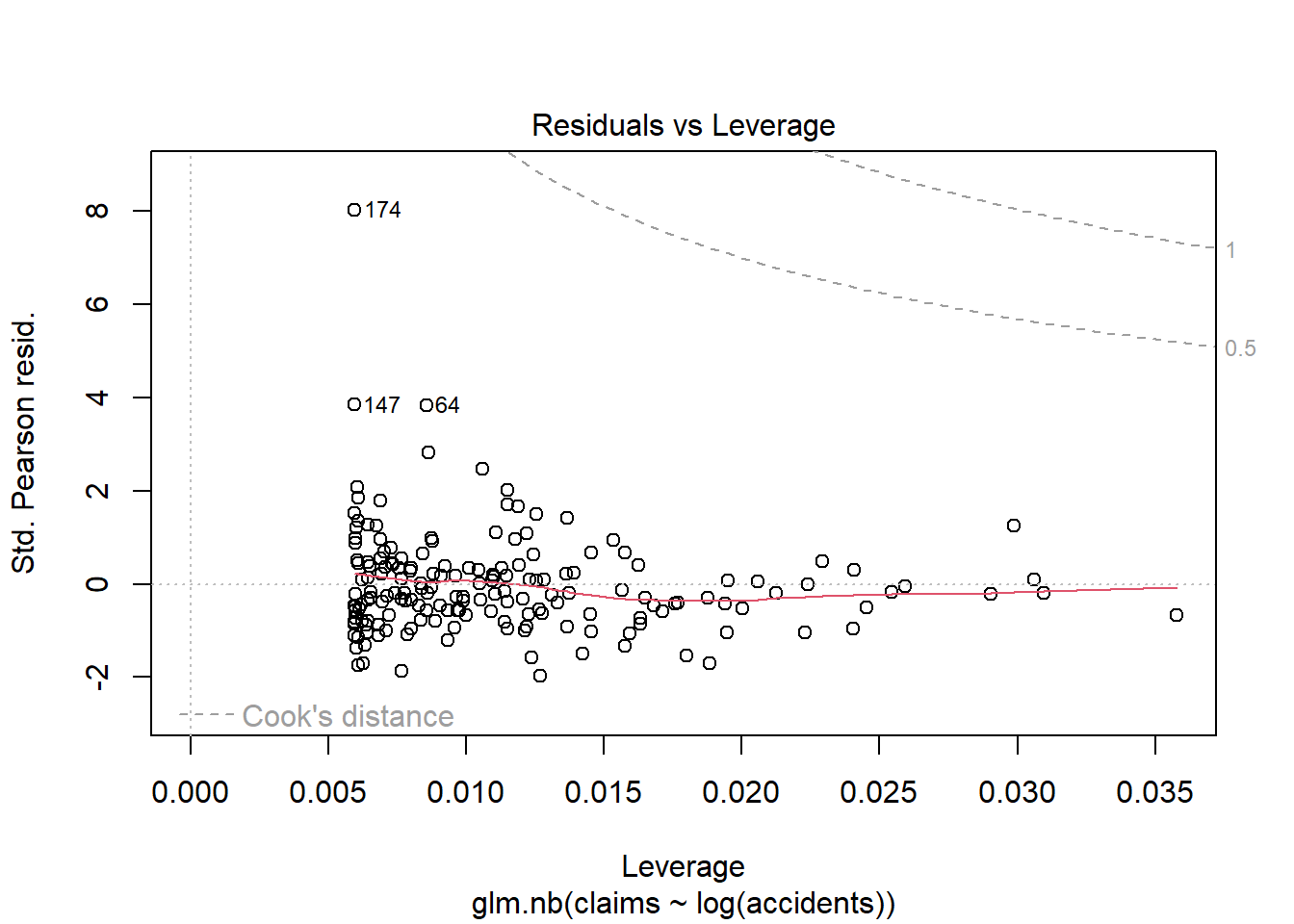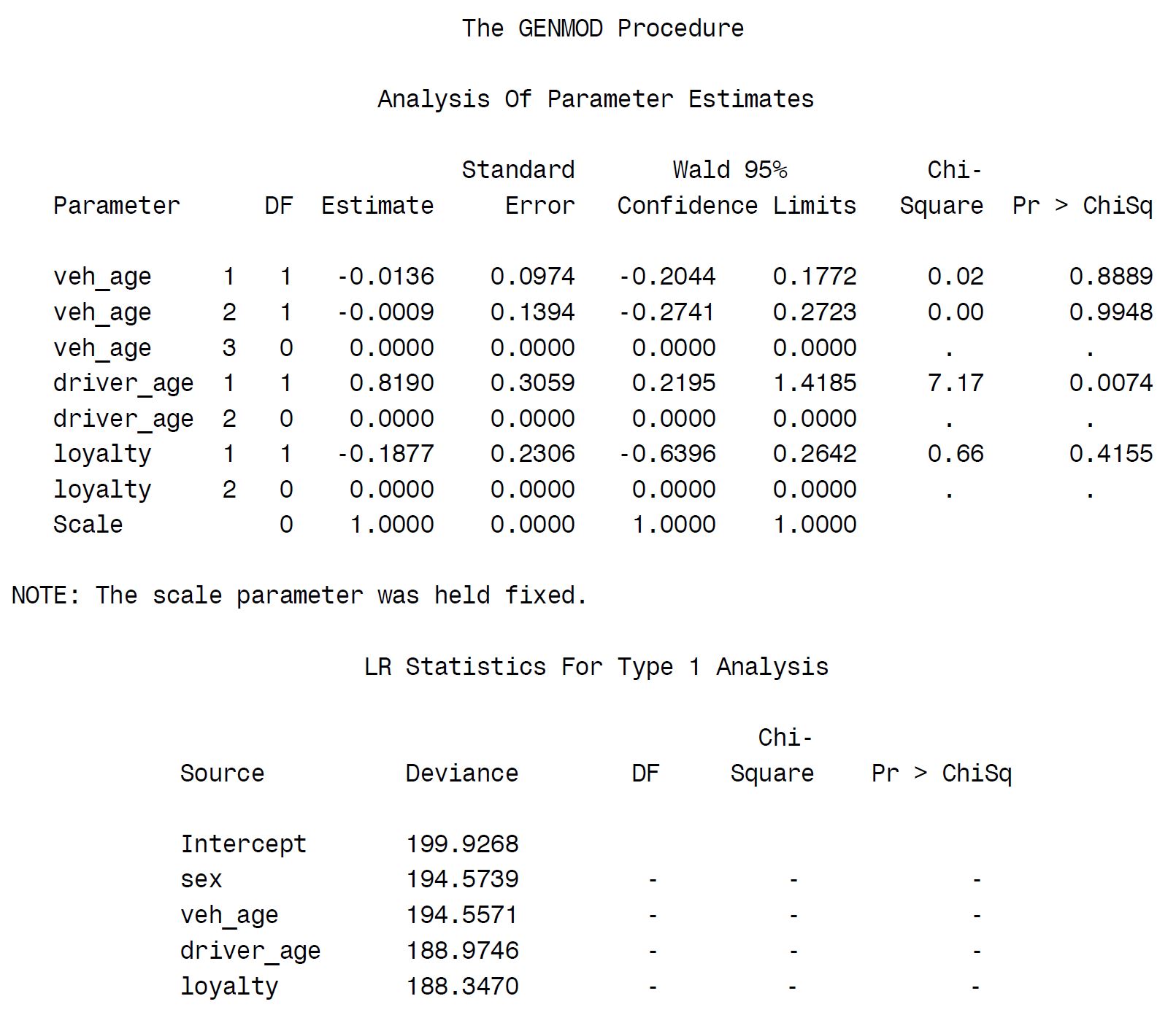
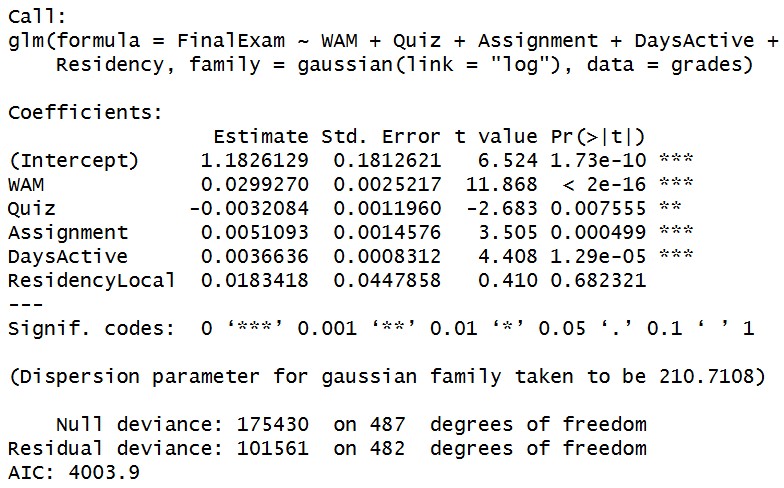
library(insuranceData)
data("dataCar")
# To get some impression on the structure of the data,
# i.e., what variables are there
names(dataCar) [1] "veh_value" "exposure" "clm" "numclaims" "claimcst0" "veh_body"
[7] "veh_age" "gender" "area" "agecat" "X_OBSTAT_"